
In the beginning of the semester we dealt with simple wireframe drawings of the models. The main reason for this is so that we did not have to deal with hidden surface removal. Now we want to deal with more sophisticated images so we need to deal with which parts of the model obscure other parts of the model.
The following sets of images show a wireframe version, a wireframe version with hidden line removal, and a solid polygonal representation of the same object.
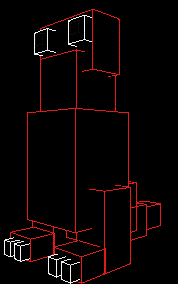

If we do not have a way of determining which surfaces are visible then which surfaces are visible depends on the order in which they are drawn with surfaces being drawn later appearing in front of surfaces drawn previously as shown below:

Here the fins on the back are visible because they are drawn after the body, the shadow is drawn on top of the monster because it is drawn last. Both legs are visible and the eyes just look really weird.
We do not want to draw surfaces that are hidden. If we can quickly compute which surfaces are hidden, we can bypass them and draw only the surfaces that are visible.
For example, if we have a solid 6 sided cube, at most 3 of the 6 sides are visible at any one time, so at least 3 of the sides do not even need to be drawn because they are the back sides.
We also want to avoid having to draw the polygons in a particular order. We would like to tell the graphics routines to draw all the polygons in whatever order we choose and let the graphics routines determine which polygons are in front of which other polygons.
With the same cube as above we do not want to have to compute for ourselves which order to draw the visible faces, and then tell the graphics routines to draw them in that order.
The idea is to speed up the drawing, and give the programmer an easier time, by doing some computation before drawing.
Unfortunately these computations can take a lot of time, so special purpose hardware is often used to speed up the process.
Two types of approaches:
object space algorithms do their work on the objects themselves before they are converted to pixels in the frame buffer. The resolution of the display device is irrelevant here as this calculation is done at the mathematical level of the objects
for each object a in the scene
determine which parts of object a are visible
(involves comparing the polyons in object a to other polygons in a
and to polygons in every other object in the scene)
image space algorithms do their work as the objects are being converted to pixels in the frame buffer. The resolution of the display device is important here as this is done on a pixel by pixel basis.
for each pixel in the frame buffer
determine which polygon is closest to the viewer at that pixel location
colour the pixel with the colour of that polygon at that location
As in our discussion of vector vs raster graphics earlier in the term the mathematical (object space) algorithms tended to be used with the vector hardware whereas the pixel based (image space) algorithms tended to be used with the raster hardware.
When we talked about 3D transformations we reached a point near the end when we converted the 3D (or 4D with homogeneous coordinates) to 2D by ignoring the Z values. Now we will use those Z values to determine which parts of which polygons (or lines) are in front of which parts of other polygons.
There are different levels of checking that can be done.
There are also times when we may not want to cull out polygons that are behind other polygons. If the frontmost polygon is transparent then we want to be able to 'see through' it to the polygons that are behind it as shown below:

Which objects are transparent in the above scene?
We used the idea of coherence before in our line drawing algorithm. We want to exploit 'local similarity' to reduce the amount of computation needed (this is how compression algorithms work.)
Rather than dealing with a complex object, it is often easier to deal with a simpler version of the object.
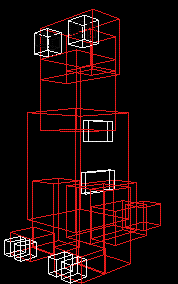
in 2: a bounding box
in 3d: a bounding volume (though we still call it a bounding box)
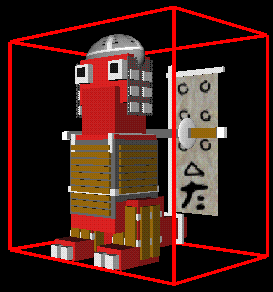
We convert a complex object into a simpler outline, generally in the shape of a box and then we can work with the boxes. Every part of the object is guaranteed to fall within the bounding box.
Checks can then be made on the bounding box to make quick decisions (ie does a ray pass through the box.) For more detail, checks would then be made on the object in the box.
There are many ways to define the bounding box. The simplest way is to take the minimum and maximum X, Y, and Z values to create a box. You can also have bounding boxes that rotate with the object, bounding spheres, bounding cylinders, etc.
Back-face culling (an object space algorithm) works on 'solid' objects which you are looking at from the outside. That is, the polygons of the surface of the object completely enclose the object.
Every planar polygon has a surface normal, that is, a vector that is normal to the surface of the polygon. Actually every planar polygon has two normals.
Given that this polygon is part of a 'solid' object we are interested in the normal that points OUT, rather than the normal that points in.
OpenGL specifies that all polygons be drawn such that the vertices are given in counterclockwise order as you look at the visible side of polygon in order to generate the 'correct' normal.
Any polygons whose normal points away from the viewer is a 'back-facing' polygon and does not need to be further investigated.
To find back facing polygons the dot product of the surface normal of each polygon is taken with a vector from the center of projection to any point on the polygon.
The dot product is then used to determine what direction the polygon is facing:
Back-face culling can very quickly remove unnecessary polygons. Unfortunately there are often times when back-face culling can not be used. For example if you wish to make an open-topped box - the inside and the ouside of the box both need to be visible, so either two sets of polygons must be generated, one set facing out and another facing in, or back-face culling must be turned off to draw that object.
in OpenGL back-face culling is turned on using:
glCullFace(GL_BACK);
glEnable(GL_CULL_FACE);
Early on we talked about the frame buffer which holds the colour for each pixel to be displayed. This buffer could contain a variable number of bytes for each pixel depending on whether it was a greyscale, RGB, or colour-indexed frame buffer. All of the elements of the frame buffer are initially set to be the background colour. As lines and polygons are drawn the colour is set to be the colour of the line or polygon at that point. T
We now introduce another buffer which is the same size as the frame buffer but contains depth information instead of colour information.
z-buffering (an image-space algorithm) is another buffer which maintains the depth for each pixel. All of the elements of the z-buffer are initially set to be 'very far away.' Whenever a pixel colour is to be changed the depth of this new colour is compared to the current depth in the z-buffer. If this colour is 'closer' than the previous colour the pixel is given the new colour, and the z-buffer entry for that pixrl is updated as well. Otherwise the pixel retains the old colour, and the z-buffer retains its old value.
Here is a pseudo-code algorithm
for each polygon
for each pixel p in the polygon's projection
{
pz = polygon's normalized z-value at (x, y); //z ranges from -1 to 0
if (pz > zBuffer[x, y]) // closer to the camera
{
zBuffer[x, y] = pz;
framebuffer[x, y] = colour of pixel p
}
}
This is very nice since the order of drawing polygons does not matter, the algorithm will always display the colour of the closest point.
The biggest problem with the z-buffer is its finite precision, which is why it is important to set the near and far clipping planes to be as close together as possible to increase the resolution of the z-buffer within that range. Otherwise even though one polygon may mathematically be 'in front' of another that difference may disappear due to roundoff error.
These days with memory getting cheaper it is easy to implement a software z-buffer and hardware z-buffering is becoming more common.
In OpenGL the z-buffer and frame buffer are cleared using:
glClear(GL_DEPTH_BUFFER_BIT | GL_COLOR_BUFFER_BIT);
In OpenGL z-buffering is turned on using:
glEnable(GL_DEPTH_TEST);
The depth-buffer is especially useful when it is difficult to order the polygons in the scene based on their depth, such as in the case shown below:

Warnock's algorithm is a recursive area-subdivision algorithm. Warnock's algorithm looks at an area of the image. If is is easy to determine which polygons are visible in the area they are drawn, else the area is subdivided into smaller parts and the algorithm recurses. Eventually an area will be represented by a single non-intersecting polygon.
At each iteration the area of interest is subdivided into four equal areas. Each polygon is compared to each area and is put into one of four bins:

For a given area:
1. If all polygons are disjoint then the background colour fills the area
2. If there is a single contained polygon or intersecting polygon then the background colour is used to fill the area, then the part of the polygon contained in the area is filled with the colour of that polygon
3. If there is a single surrounding polygon and no intersecting or contained polygons then the area is filled with the colour of the surrounding polygon
4. If there is a surrounding polygon in front of any other surrounding, intersecting, or contained polygons then the area is filled with the colour of the front surrounding polygon
Otherwise break the area into 4 equal parts and recurse.
At worst log base 2 of the max(screen width, screen height) recursive steps will be needed. At that point the area being looked at is only a single pixel which can't be divided further. At that point the distance to each polygon intersecting,contained in, or surrounding the area is computed at the center of the polygon to determine the closest polygon and its colour,
Below is an example scanned out of the text, where the numbers refer to the numbered steps listed above:
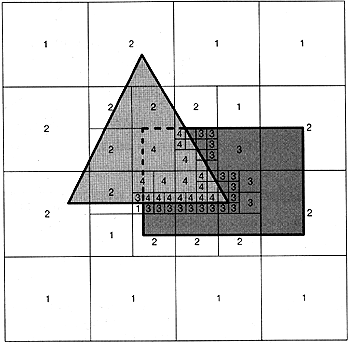
Here is a place where the use of bounding boxes can speed up the process. Given that the bounding box is always at least as large as the polygon, or object checks for contained and disjoint polygons can be made using the bounding boxes, while checks for interstecting and surrounding can not.
The idea here is to go back to front drawing all the objects into the frame buffer with nearer objects being drawn over top of objects that are further away.
Simple algorithm:
This algorithm would be very simple if the z coordinates of the polygons were guaranteed never to overlap. Unfortunately that is usually not the case, which means that step 2 can be somewhat complex.
Any polygons whose z extents overlap must be tested against each other.
We start with the furthest polygon and call it P. Polygon P must be compared with every polygon Q whose z extent overlaps P's z extent. 5 comparisons are made. If any comparison is true then P can be written before Q. If at least one comparison is true for each of the Qs then P is drawn and the next polygon from the back is chosen as the new P.
If all 5 tests fail we quickly check to see if switching P and Q will work. Tests 1, 2, and 5 do not differentiate between P and Q but 3 and 4 do. So we rewrite 3 and 4
3 - is Q entirely on the opposite side of P's plane from the
viewport.
4 - is P entirely on the same side of Q's plane as the viewport.
If either of these two tests succeed then Q and P are swapped and the new P (formerly Q) is tested against all the polygons whose z extent overlaps it's z extent.
If these two tests still do not work then either P or Q is split into 2 polygons using the plane of the other. These 2 smaller polygons are then put into their proper places in the sorted list and the algorithm continues.
beware of the dreaded infinite loop.
Another popular way of dealing with these problems (especially in games) are Binary Space Partition trees. It is a depth sort algorithm with a large amount of preprocessing to create a data structure to hold the polygons.
First generate a 3D BSP tree for all of the polygons in the scene
Then display the polygons according to their order in the scene
Each node in the tree is a polygon. Extending that polygon generates a plane. That plane cuts space into 2 parts. We use the front-facing normal of the polygon to define the half of the space that is 'in front' of the polygon. Each node has two children: the front children (the polygons in front of this node) and the back children (the polgons behind this noce)
In doing this we may need to split some polygons into two.
Then when we are drawing the polygons we first see if the viewpoint is in front of or behind the root node. Based on this we know which child to deal with first - we first draw the subtree that is further from the viewpoint, then the root node, then the subtree that is in front of the root node, recursively, until we have drawn all the polygons.
Compared to depth sort it takes more time to setup but less time to iterate through since there are no special cases.
If the position or orientation of the polygons change then parts of the tree will need to be recomputed.
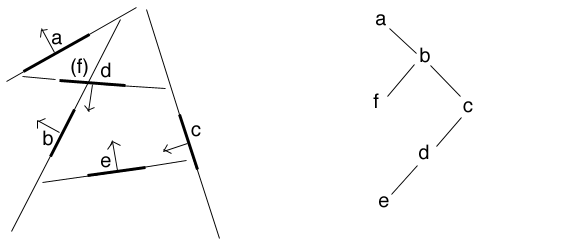
here is an example originally by Nicolas Holzschuch showing the construction and use of a BSP tree for 6 polygons.

This is an extension of the algorithm we dealt with earlier to fill polygons one scan line at a time. This time there will be multiple polygons being drawn simultaneously.
Again we create a global edge table for all non-horizontal edges sorted based on the edges smaller y coordinate.
Each entry in the table contains:
and a new entry
In the scan line algorithm we had a simple 0/1 variable to deal with being in or out of the polygon. Since there are multiple polygons here we have a Polygon Table.
The Polygon Table contains:
Again the edges are moved from the global edge table to the active edge table when the scan line corresponding to the bottom of the edge is reached.
Moving across a scan line the flag for a polygon is flipped when an edge of that polygon is crossed.
If no flags are true then nothing is drawn
If one flag is true then the colour of that polygon is used
If more than one flag is true then the frontmost polygon must
be determined.
Below is an example from the textbook (figure red:13.11, white:15.34)

Here there are two polygons ABC and DEF
Scan Line AET contents Comments --------- ------------ -------- alpha AB AC one polygon beta AB AC FD FE two separate polygons gamma AB DE CB FE two overlapping polygons gamma+1 AB DE CB FE two overlapping polygons gamma+2 AB CB DE FE two separate polygons
A simple ray-tracing algorithm can be used to find visible surfaces, as opposed to a more complicated algorithm that can be used to generate those o-so-pretty images.
Ray tracing is an image based algorithm. For every pixel in the image, a ray is cast from the center of projection through that pixel and into the scene. The colour of the pixel is set to the colour of the object that is first encountered.
Given a Center Of Projection
Given a window on the viewplane
for (each scan line)
for (each pixel on the scan line)
{
compute ray from COP through pixel
for (each object in scene)
if (object is intersected by ray
&& object is closer than previous intersection)
record (intersection point, object)
set pixel's colour to the colour of object at intersection point
}
So, given a ray (vector) and an object the key idea is computing if and if so where does the ray intersect the object.
the ray is represented by the vector from (Xo, Yo, Zo) at the COP, to (X1, Y1, Z1) at the center of the pixel. We can parameterize this vector by introducing t:
X = Xo + t(X1 - Xo)
Y = Yo + t(Y1 - Yo)
Z = Zo + t(Z1 - Zo)
or
X = Xo + t(deltaX)
Y = Yo + t(deltaY)
Z = Zo + t(deltaZ)
t equal to 0 represents the COP, t equal to 1 represents the
pixel
t < 0 represents points behind the COP
t > 1 represents points on the other side of the view plane
from the COP
We want to find out what the value of t is where the ray intersects the object. This way we can take the smallest value of t that is in front of the COP as defining the location of the nearest object along that vector.
The problem is that this can take a lot of time, especially if there are lots of pixels and lots of objects.
The raytraced images in 'Toy Story' for example took at minimum 45 minutes and at most 20 hours for a single frame.
So minimizing the number of comparisons is critical.
- Bounding boxes can be used to perform initial checks on complicated objects
- hierarchies of bounding boxes can be used where a successful intersection with a bounding box then leads to tests with several smaller bounding boxes within the larger bounding box.
- The space of the scene can be partitioned. These partitions are then treated like buckets in a hash table, and objects within each partition are assigned to that partition. Checks can then be made against this constant number of partitions first before going on to checking the objects themselves. These partitions could be equal sized volumes, or contain equal numbers of polygons.
Full blown ray tracing takes this one step further by reflecting rays off of shiny objects, to see what the ray hits next, and then reflecting the ray off of that, and so on, until a limiting number of reflections have been encountered. For transparent or semi-transparent objects, rays are passed through the object, taking into account any deflection or filtering that may take place ( e.g. through a colored glass bottle or chess piece ), again proceeding until some limit is met. Then the contributions of all the reflections and transmissions are added together to determine the final color value for each pixel. The resulting images can be incredibly beautiful and realistic, and usually take a LONG time to compute.
From table 13.1 in the red book (15.3 in the white book) the relative performance of the various algorithms where smaller is better and the depth sort of a hundred polygons is set to be 1.
# of polygonal faces in the scene Algorithm 100 250 60000 -------------------------------------------------- Depth Sort 1 10 507 z-buffer 54 54 54 scan line 5 21 100 Warnock 11 64 307
This table is somewhat bogus as z-buffer performance degrades as the number of polygonal faces increases.
To get a better sense of this, here are the number of polygons in the following models:
250 triangular polygons:
550 triangular polygons:
6,000 triangular polygons:
(parrot by Christina Vasilakis)

8,000 triangular polygons: 
10,000 triangular polygons:
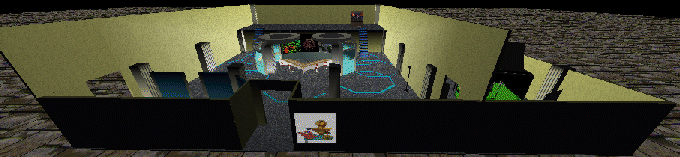
(ARPA Integration testbed space by Jason Leigh, Andrew Johnson,
Mike Kelley)