University of Illinois Chicago
I am very interested in data-efficient approaches to computer vision, particularly those that learn from unlabeled or weakly labeled data, for two reasons. First, this direction is crucial for real-world applications, where collecting and annotating large-scale datasets is expensive, time-consuming, or even infeasible. Reducing or eliminating the reliance on large amounts of annotated data allows for great scalability and adaptability across a wide range of domains. Second, it often sheds light on the fundamental principles of computer vision. Designing methods that perform well in this setting requires deep insight into the intrinsic structure and formation of visual data and the nature of visual perception, ultimately advancing our theoretical understanding of the field. I have investigated data-efficient approaches for a variety of vision tasks, from recognizing and locating objects in an image, to estimating shape and pose in 3D space, and understanding motion and action in videos. They are summarized below.
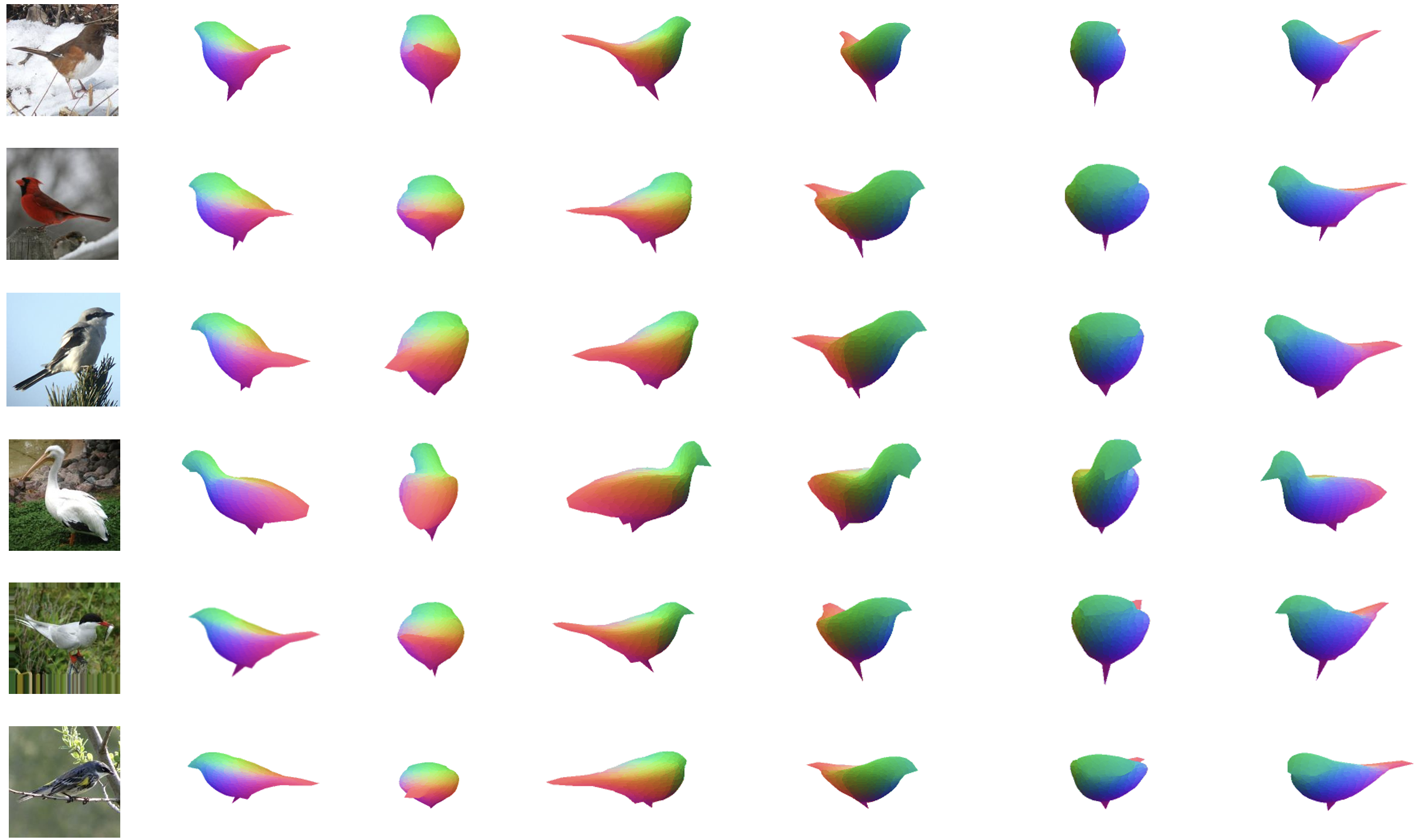
We introduce an Analysis-by-Synthesis Transformer to learn single-view 3D reconstruction from a collection of images with only 2D mask annotations. It addresses core challenges of the analysis-by-synthesis paradigm through effective pixel-to-shape and pixel-to-texture modeling. More recently, we extend this work for partonomic 3D reconstruction, aiming not only to recover an object’s shape from a single image but also to decompose it into semantic parts. This task is crucial for real-world applications such as fine-grained robotic manipulation but remains largely underexplored. To handle the expanded solution space and frequent part occlusions in single-view images, we propose a novel approach that represents, parses, and learns the structural compositionality of 3D objects
Xiaoqian Ruan, Pei Yu, Dian Jia, Hyeonjeong Park, Peixi Xiong, and Wei Tang, "Learning Partonomic 3D Reconstruction from Image Collections," IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025.
Dian Jia, Xiaoqian Ruan, Kun Xia, Zhiming Zou, Le Wang, and Wei Tang, "Analysis-by-Synthesis Transformer for Single-View 3D Reconstruction," European Conference on Computer Vision (ECCV), 2024.

To our knowledge, this is the first work for unsupervised learning of joint landmark detection and pose estimation. On the one hand, it provides a new direction to address the rigid pose estimation problem, which commonly requires large amounts of pose or landmark annotations. On the other hand, it is the first attempt to explicitly consider the 3D object structure for 3D-aware landmark discovery. Specifically, we propose a new approach that models the 2D landmarks, rigid pose, and 3D canonical landmarks in a unified framework. They are learned collaboratively on unlabeled images through an integrated loss of conditional image generation and geometric consistency. We also propose a simple and effective method to avoid the adverse effect of nonrigid deformation on our framework.
Zhiming Zou, Dian Jia, and Wei Tang, "Towards Unsupervised Learning of Joint Facial Landmark Detection and Head Pose Estimation," Pattern Recognition (PR), 2025.
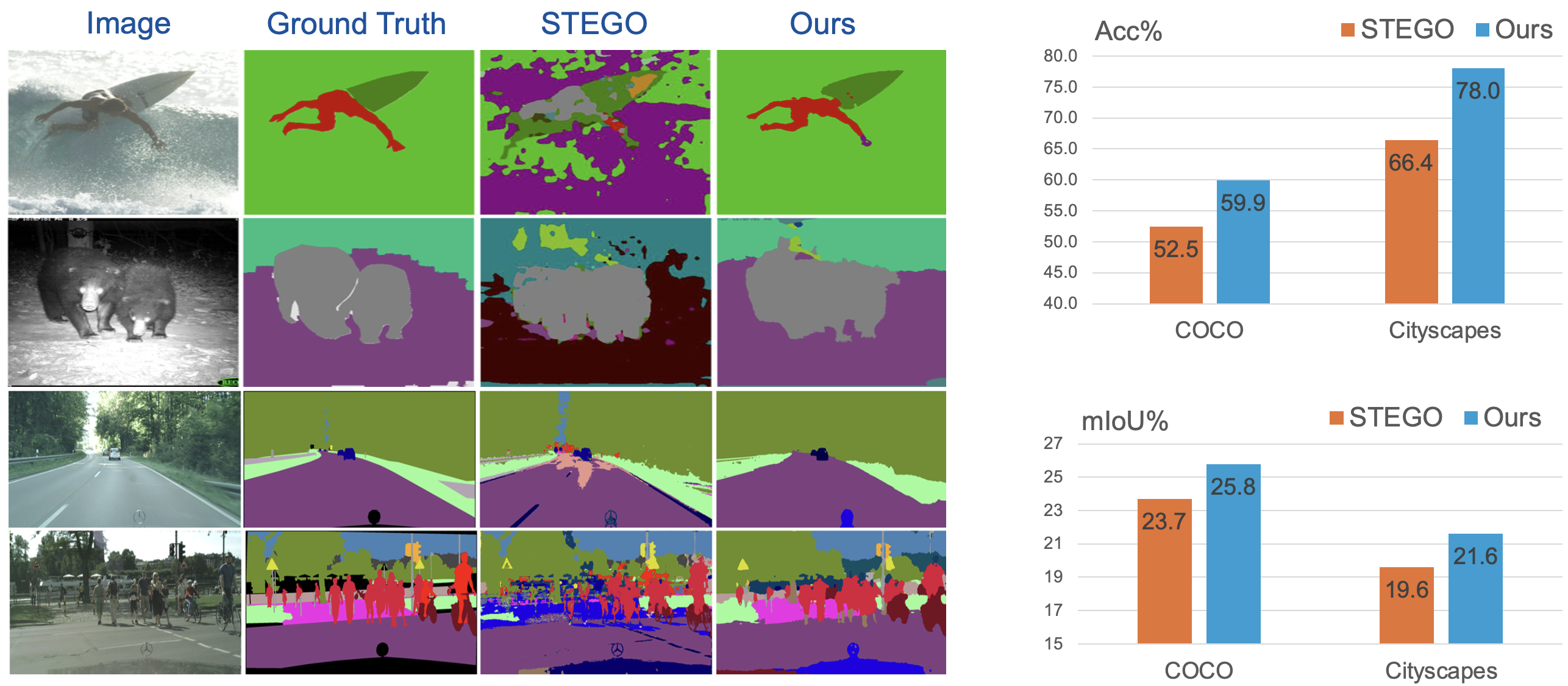
Unsupervised semantic segmentation (USS) is valuable because it eliminates the need for costly dense pixel labeling and helps discover new visual patterns that are not known before. However, current approaches face several critical challenges: (1) their two-stage frameworks cannot coordinate representation learning and pixel clustering; (2) their dependence on generative clustering, typically K-means, imposes restrictive assumptions about cluster shapes; (3) the severe pixel class imbalance in real-world images has been ignored in the unsupervised setting. This work addresses all these challenges through a novel USS framework that jointly learns dense feature representations and pixel labeling in a discriminative, end-to-end, and self-supervised manner. The core of our approach is a new learning objective that transfers the manifold structure of pixels in the Vision Transformer (ViT) embedding space to the label space while tolerating the noise in pixel affinities. Additionally, we propose a new regularizer, based on the Weibull function, that addresses both cluster degeneration and pixel class imbalance at once. At inference time, the trained model directly outputs per-pixel classification probabilities conditioned on the input image. The entire framework is trained in a single-stage, end-to-end fashion, and does not require any post-training clustering methods, such as K-means.
Mingyuan Liu, Jicong Zhang, and Wei Tang, "Imbalance-Aware Discriminative Clustering for Unsupervised Semantic Segmentation," International Journal of Computer Vision (IJCV), 2024.
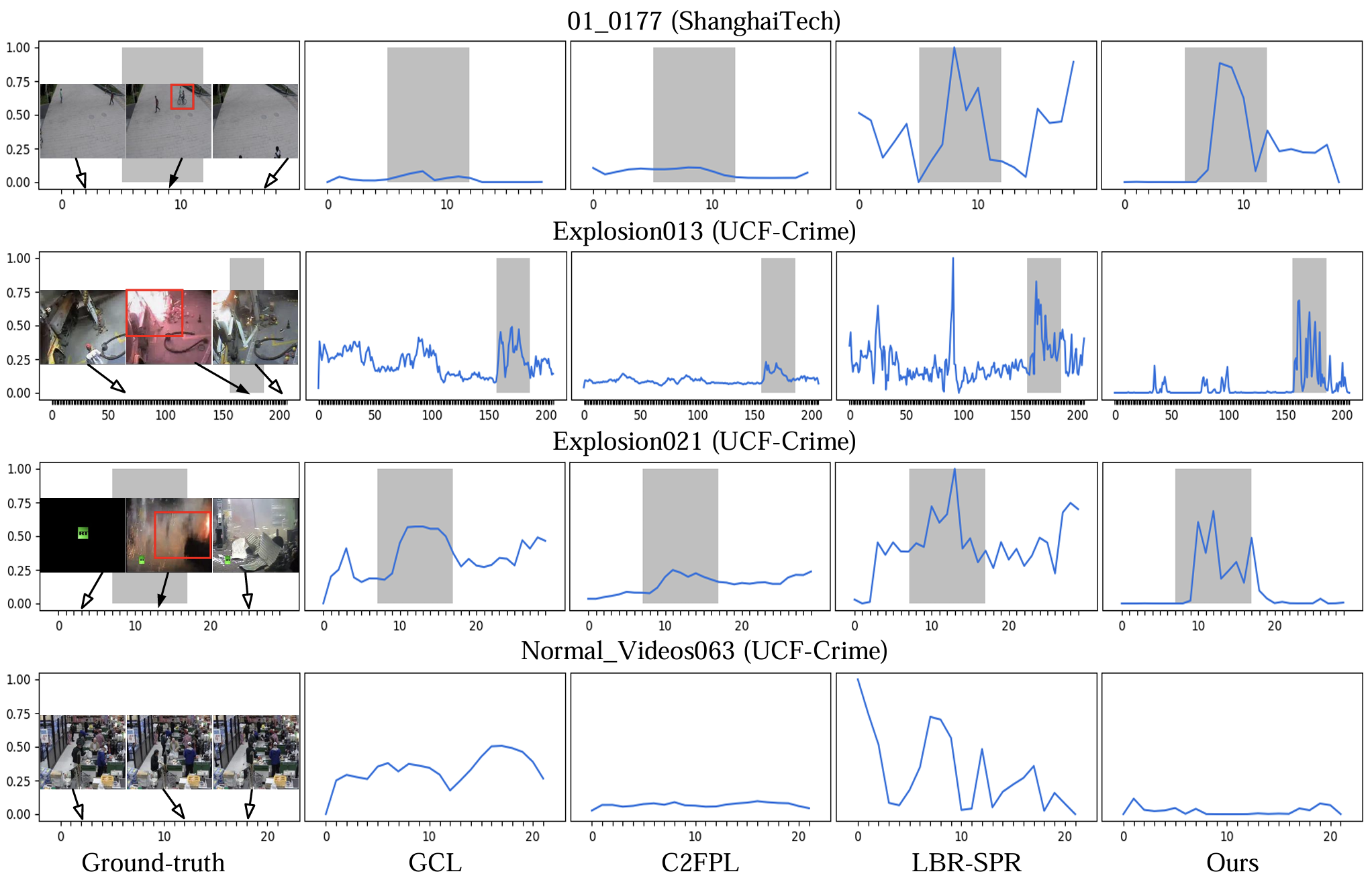
Unsupervised video anomaly detection (UVAD) aims to detect abnormal events in videos without any annotations. It remains challenging because anomalies are rare, diverse, and usually not well-defined. Existing UVAD methods are purely data-driven and perform unsupervised learning by identifying various abnormal patterns in videos. Since these methods largely rely on the feature representation and data distribution, they can only learn salient anomalies that are substantially different from normal events but ignore the less distinct ones. To address this challenge, this work pursues a different approach that leverages data-irrelevant prior knowledge about normal and abnormal events for UVAD. We first propose a new normality prior for UVAD, suggesting that the start and end of a video are predominantly normal. We then propose normality propagation, which propagates normal knowledge based on relationships between video snippets to estimate the normal magnitudes of unlabeled snippets. Finally, unsupervised learning of abnormal detection is performed based on the propagated labels and a new loss re-weighting method.
Haoyue Shi, Le Wang, Sanping Zhou, Gang Hua, and Wei Tang, "Learning Anomalies with Normality Prior for Unsupervised Video Anomaly Detection," European Conference on Computer Vision (ECCV), 2024.
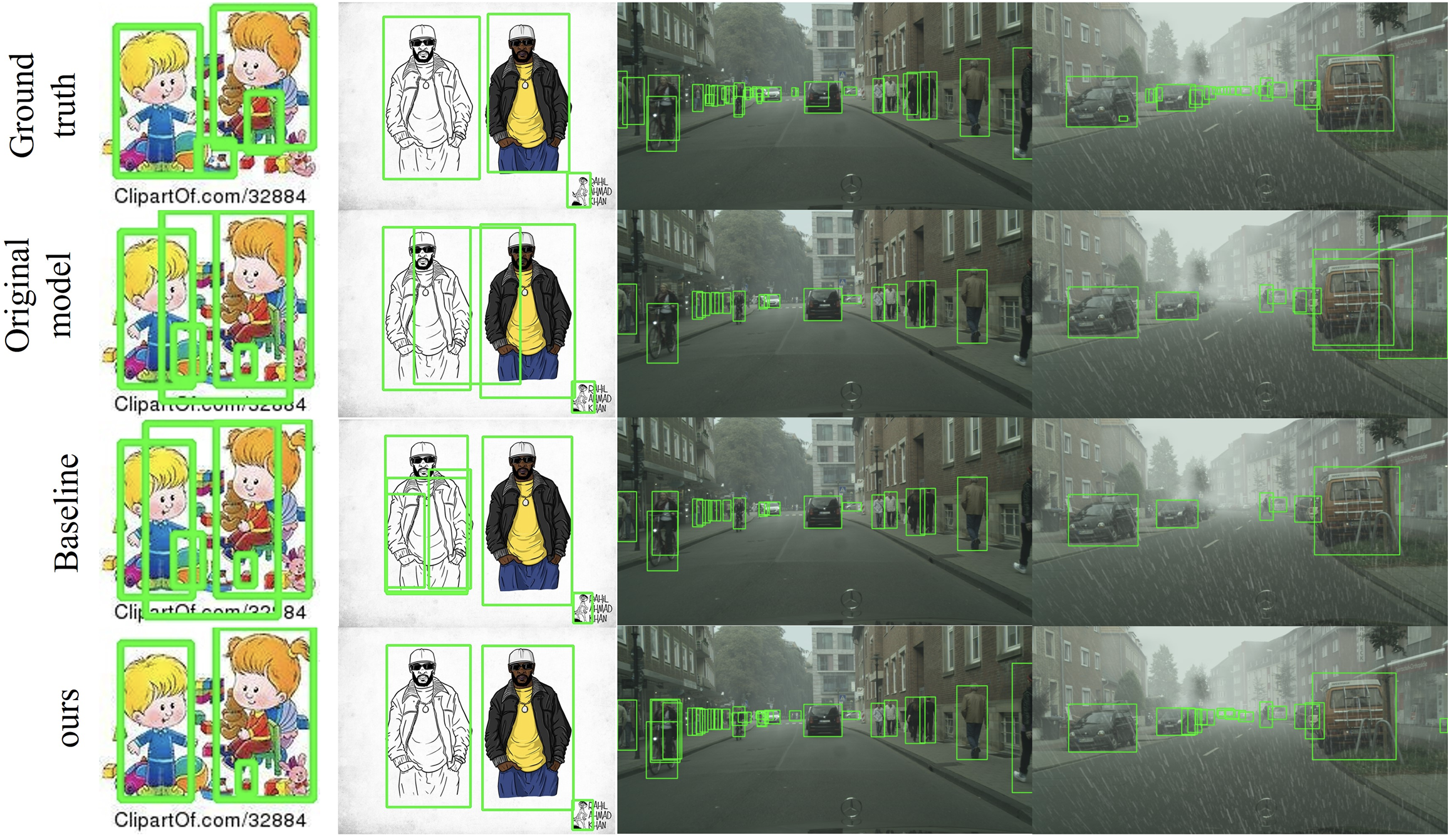
To our knowledge, this is the first work on fully test-time adaptation for object detection. It means to update a trained object detector on a single testing image before making a prediction, without access to the training data. Compared with the popular unsupervised domain adaptation (UDA) and source-free domain adaptation (SFDA), it neither assumes a stationary and known target domain nor requires access to a target dataset. This is desired in many image understanding applications, where the target domain is unknown a prior and differs from image to image. Through a diagnostic study of a baseline self-training framework, we show that a great challenge of this task is the unreliability of pseudo labels caused by domain shift. We then propose a simple yet effective method, termed the IoU Filter, to address this challenge. It consists of two new IoU-based indicators, both of which are complementary to the detection confidence. Experimental results on five datasets demonstrate that our approach could effectively adapt a trained detector to various kinds of domain shifts at test time and bring substantial performance gains.
Xiaoqian Ruan and Wei Tang, "Fully Test-time Adaptation for Object Detection," IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2024.
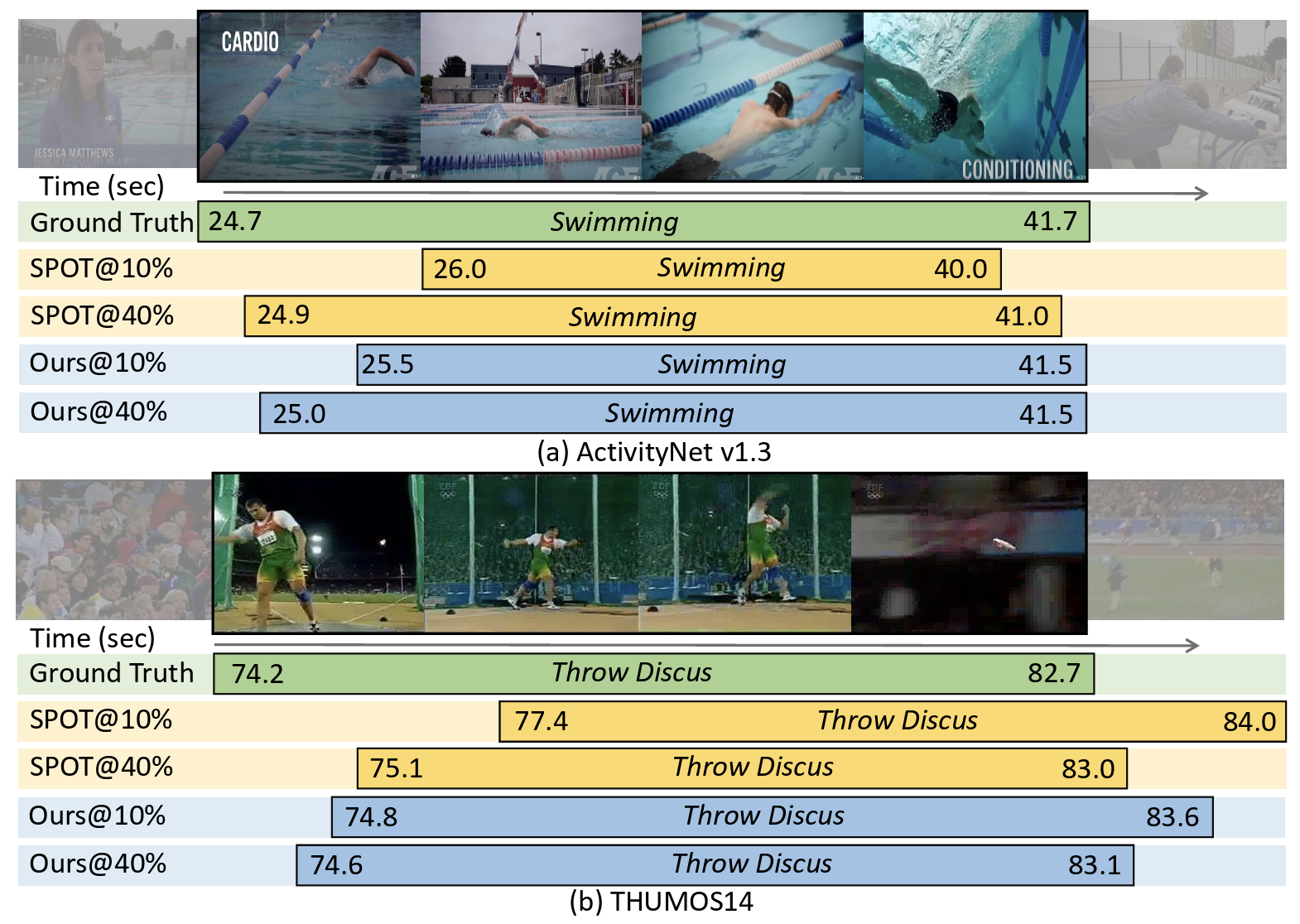
Semi-Supervised Temporal Action Localization (SS-TAL) aims to improve the generalization ability of action detectors with large-scale unlabeled videos. Albeit the recent advancement, one of the major challenges still remains: noisy pseudo labels hinder efficient learning on abundant unlabeled videos, embodied as location biases and category errors. In this paper, we dive deep into such an important but understudied dilemma. To this end, we propose a unified framework, termed Noisy Pseudo-Label Learning, to handle both location biases and category errors. Specifically, our method is featured with (1) Noisy Label Ranking to rank pseudo labels based on the semantic confidence and boundary reliability, (2) Noisy Label Filtering to address the class-imbalance problem of pseudo labels caused by category errors, (3) Noisy Label Learning to penalize in-consistent boundary predictions to achieve noise-tolerant learning for heavy location biases. As a result, our method could effectively handle the label noise problem and improve the utilization of a large amount of unlabeled videos. Extensive experiments on THUMOS14 and ActivityNet v1.3 demonstrate the effectiveness of our method.
Kun Xia, Le Wang, Sanping Zhou, Gang Hua, and Wei Tang, "Learning from Noisy Pseudo Labels for Semi-Supervised Temporal Action Localization," IEEE/CVF International Conference on Computer Vision (ICCV), 2023.