University of Illinois Chicago
Compositionality refers to the evident capability of humans to represent entities as hierarchies of substructures, which themselves are meaningful and reusable entities. It is believed to be fundamental to all forms of human cognition. In computer vision, compositionality plays a crucial role in three primary ways. First, it decomposes high-dimensional visual entities, e.g., object shapes and articulated motions, into lower-dimensional substructures, which are less variable and easier to model. Second, the mutual constraints among these substructures facilitate effective learning from limited training data and enable robust inference in the presence of ambiguities, such as occlusion. Third, compositional models provide a deep and interpretable understanding of visual entities through structural parsing and primitive grounding.
The pioneering research on general compositional models can be traced back to King Sun Fu’s syntactic pattern recognition and Ulf Grenander’s pattern theory in the 1970s. Since then, compositionality has been studied in several lines of vision research, for example, Stuart Geman’s composition machine, Song-Chun Zhu’s And-Or graph, Alan Yuille’s recursive compositional model, and Pedro Felzenszwalb’s object detection grammar. These approaches are built on probabilistic models or stochastic grammars.
The study of visual compositionality in the deep era is still in its early stages. The composition network developed in my Ph.D. thesis is the first work that integrates deep learning and stochastic grammars in vision, by formulating probabilistic compositional inferences as bottom-up/top-down And, Or, and Primitive-layers and learning them end-to-end. My recent research on visual compositionality has focused on three main directions: part-whole structure of physical objects, object dependency in visual scenes, and part dependency in articulated bodies. They are summarized below. I am currently also investigating compositionality of physical scenes.
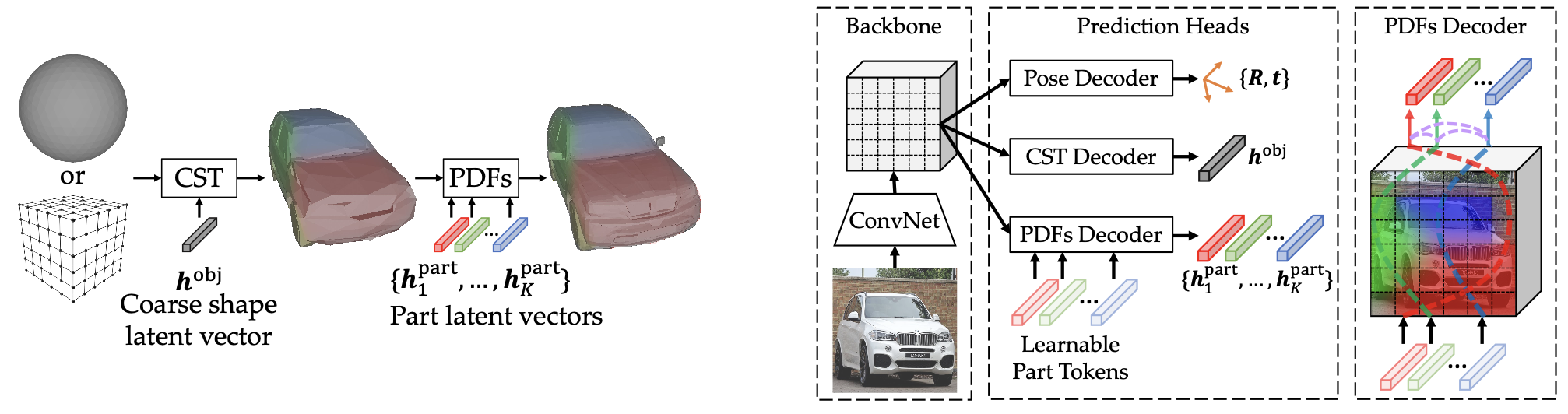
Our recent project investigates learning the part-whole structure of physical objects from image data using only 2D annotations. This capability is essential for intelligent agents that interact with the physical world, such as robots manipulating objects. We address this important yet largely unexplored task by representing, parsing, and learning the geometric compositionality of 3D objects.
Our new approach comprises: (1) a compact and expressive compositional representation of object geometry, achieved through disentangled modeling of large shape variations, constituent parts, and detailed part deformations as multi-granularity neural fields; (2) a part-based transformer that recovers precise partonomic geometry and handles occlusions, through effective part-to-pixel grounding and part-to-part relational modeling; and (3) a self-supervised learning method that jointly learns the compositional representation and part-based transformer, by bridging object shape and parts, image synthesis, and differentiable rendering. Extensive experiments on ShapeNetPart, PartNet, and CUB-200-2011 demonstrate the effectiveness of our approach on both object and part reconstruction.
Xiaoqian Ruan, Pei Yu, Dian Jia, Hyeonjeong Park, Peixi Xiong, and Wei Tang, “Learning Partonomic 3D Reconstruction from Image Collections,” IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025.
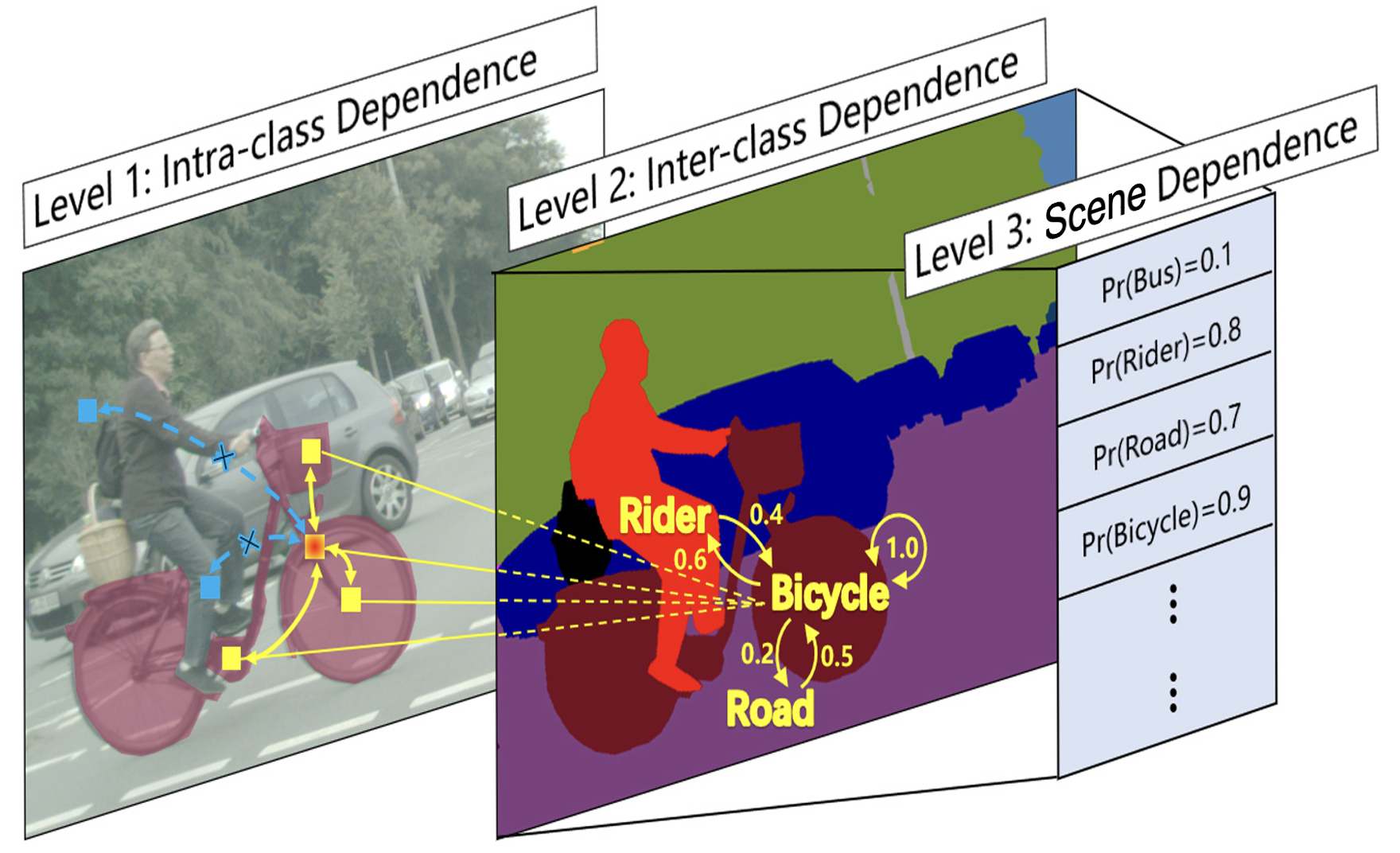
Visual dependency is ubiqitous, as both objects and scenes are inherently structured. It offers rich prior knowledge about the real world, which in turn enhances generalizability in visual understanding. In this work, we introduce a novel approach that integrates explicit visual dependency modeling with data-driven deep learning, combining the strengths of both paradigms. Central to this approach is a set of new mechanisms that perform visual dependency reasoning at three distinct levels.
First, intra-class dependency refers to the relationships among parts within an object, stemming from its internal structural patterns, e.g., a bicycle comprising wheels, pedals and a frame. Second, inter-class dependency captures the co-occurrence of different objects within a scene, as certain objects (e.g., a rider and a bicycle) tend to appear together more frequently than others or by chance. Third, scene-level dependency reflects how the type of a scene imposes strong priors on the categories of objects likely to be present. For instance, it is uncommon to see a pedestrian on a highway.
Our experiments demonstrate that each dependency model improves semantic segmentation performance, and they are complementary. In recent work (currently under review), we extend this framework from 2D pixel labeling to 3D voxel labeling by modeling and learning visual dependencies in the physical world. Our results show substantial performance gains on minority classes as well as overall improvements over the state of the art.
Mingyuan Liu, Dan Schonfeld, and Wei Tang, "Exploit Visual Dependency Relations for Semantic Segmentation," IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
Modeling dependencies between parts is crucial for articulated pose and motion estimation, as these dependencies help constrain the vast solution space caused by the high degrees of freedom and resolve visual ambiguities such as occlusion and clutter. We have developed novel approaches that model articulated part dependencies from two distinct perspectives: multi-task learning for 2D pose estimation and graph networks for lifting 2D poses to 3D.
Articulated body pose estimation is inherently a homogeneous multi-task learning problem, with the localization of each body part as a different task. All existing methods learn a shared representation for all parts, from which their locations are linearly regressed. However, our statistical analysis indicates not all parts are related to each other. As a result, such a sharing mechanism can lead to negative transfer and deteriorate the performance. This potential issue drives us to raise an interesting question: Can we identify related parts and learn specific features for them to improve pose estimation? Since unrelated tasks no longer share a high-level representation, we expect to avoid the adverse effect of negative transfer. In addition, more explicit structural knowledge, e.g., ankles and knees are highly related, is incorporated into the model, which helps resolve ambiguities in pose estimation. To answer this question, we first propose a data-driven approach to group related parts based on how much information they share. Then a part-based branching network is introduced to learn representations specific to each part group. We further present a multi-stage version of this network to repeatedly refine intermediate features and pose estimates. Our extensive experiments indicate learning specific features significantly improves the localization of occluded parts and thus benefits articulated body pose estimation.
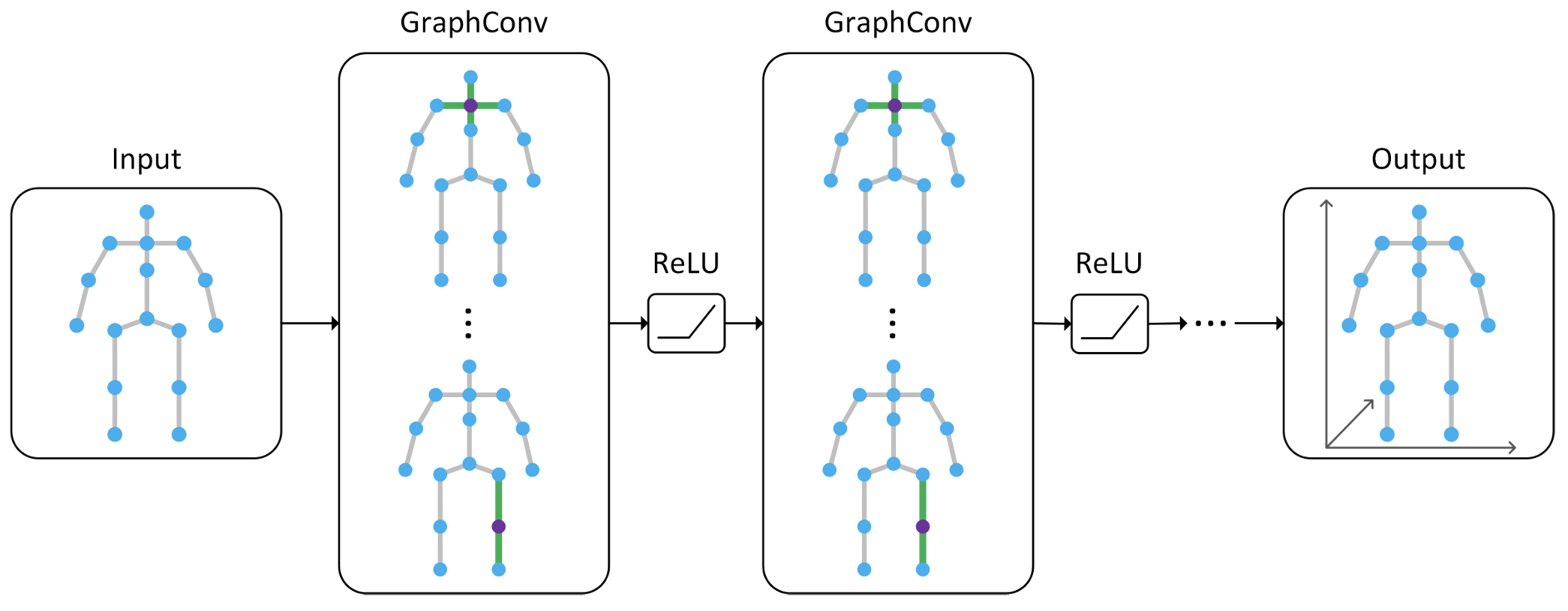
By treating each 2D part localization as a node and the articulated skeleton as a graph, the recently very popular graph convolutional networks (GCNs) are very suitable for 2D-to-3D articulated pose lifting. However, the vanilla graph convolution suffers from two fundamental limitations. First, it shares a feature transformation for each node and thus prevents the model from learning different relations between different body parts. Second, simply constructing the graph structure based on the human skeleton is suboptimal because human activities often exhibit motion patterns beyond the natural connections of body parts. We introduce a novel Modulated GCN to close the gap. It consists of two main components: weight modulation and affinity modulation. Weight modulation learns different modulation vectors for different nodes so that the feature transformations of different nodes are disentangled while retaining a small model size. Affinity modulation adjusts the graph structure in a GCN so that it can model additional edges beyond the human skeleton. Compared with state-of-the-art methods, our approach either significantly reduces the estimation errors, e.g., by around 10%, while retaining a small model size or drastically reduces the model size, e.g., from 4.22M to 0.29M (a 14.5× reduction), while achieving comparable performance.
Zhiming Zou and Wei Tang, "Modulated Graph Convolutional Network for 3D Human Pose Estimation," IEEE/CVF International Conference on Computer Vision (ICCV), 2021.
Kenkun Liu, Rongqi Ding, Zhiming Zou, Le Wang, and Wei Tang, "A Comprehensive Study of Weight Sharing in Graph Networks for 3D Human Pose Estimation," European Conference on Computer Vision (ECCV), 2020.
Wei Tang and Ying Wu, "Does Learning Specific Features for Related Parts Help Human Pose Estimation?," IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
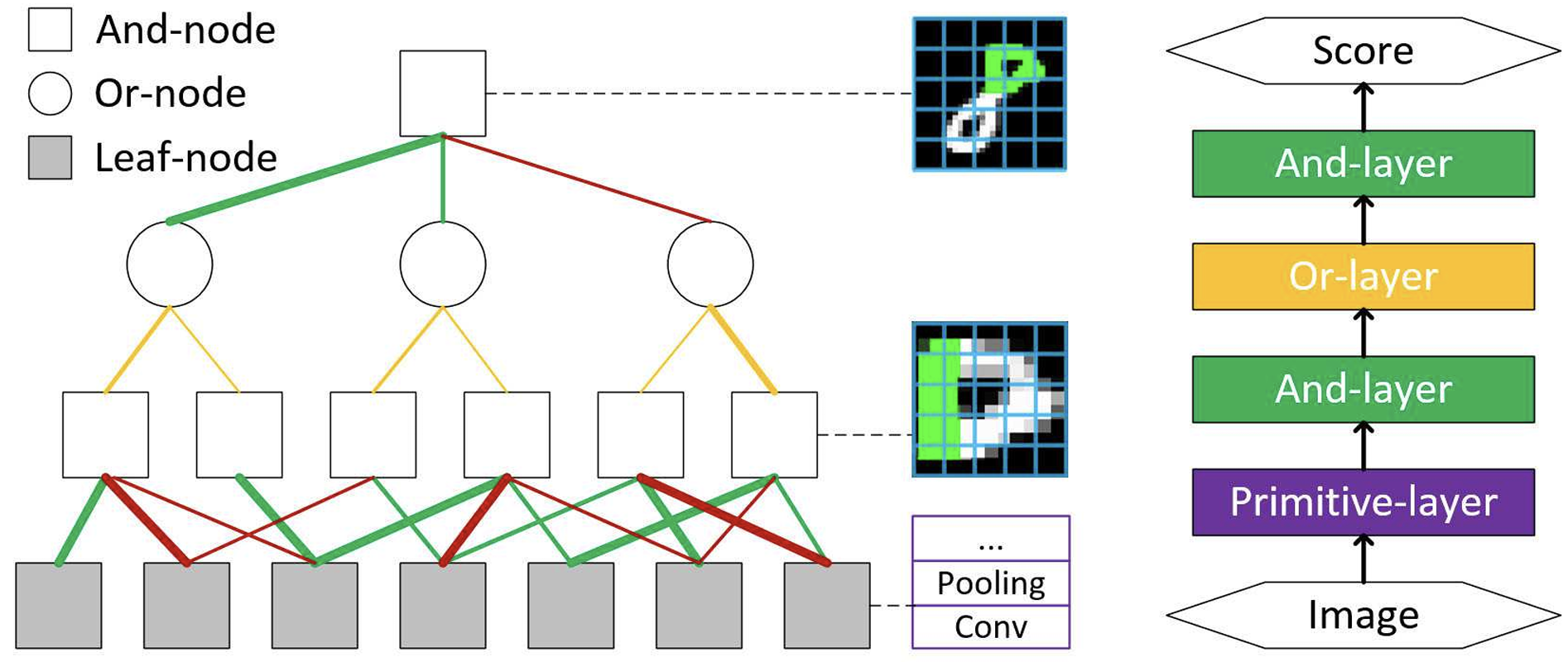
Stochastic grammars, particularly And-Or Graphs, have been the prevailing tools for modeling and learning visual compositionality, but they faced significant challenges in structure discovery, primitive grounding, and efficient learning.
To address these challenges, we quest for a unified framework for compositional pattern modeling, inference, and learning, by seamlessly integrating stochastic grammars and deep learning.
Represented by And-Or graphs, this new framework, termed the composition network, jointly models the compositional structure, parts, features, and composition/sub-configuration relationships. We show that its inference algorithm is equivalent to a feed-forward network. Thus, all the parameters can be learned efficiently via the highly-scalable back-propagation. Consequently, through bottom-up/top-down compositional inferences across And, Or, and Primitive-layers, the composition network learns to parse visual entities, e.g., objects and human bodies, into hierarchies of parts and subparts in an end-to-end fashion. We have demonstrated the effectiveness of the composition network in a range of tasks, including natural scene character recognition, generic object detection, and human pose estimation.
Wei Tang, Pei Yu, and Ying Wu, "Deeply Learned Compositional Models for Human Pose Estimation," European Conference on Computer Vision (ECCV), 2018.
Wei Tang, Pei Yu, Jiahuan Zhou, and Ying Wu, "Towards a Unified Compositional Model for Visual Pattern Modeling," IEEE International Conference on Computer Vision (ICCV), 2017.