CORBA
1. Introduction
1.1 Java and CORBA
Java offers CORBA:
- a pure object-oriented language: vs. COBOL or C; advantages
over C++ (including exceptions, threads, and the standard
library); straightforward mapping from IDL
- portability and platform-independence (without recompiling): the
standard library includes CORBA base classes, the JDK includes an ORB
- web integration: servlets (using threads and library
functionality) and JSP vs CGI, applets as thin clients (rather
than HTML "null" clients) or CORBA clients (standard access to
distributed services)
- component models: Enterprise Java Beans (EJB) is a subset of the
CORBA Component Model and uses IIOP so it can interact with CORBA
(development roles, design patterns: stateless/ful session beans and
entity beans, configurable infrastructure service, etc.)
CORBA offers Java:
- implementation-independent interfaces: IDL, software development
process, maintenance
- access to applications and objects written in other languages:
IDL-language mappings
- location transparency, server configuration and activation (via
POA)
- automatic stub and skeleton generation: networking, sockets,
marshalling
- access to CORBA services and facilities: naming, trading,
notification, transactions, persistence, security, etc.
CORBA and RMI:
- both have implementation-independent interfaces, location
transparency, activation, automatic stub (and skeleton) generation
- RMI is simpler to use, but has fewer services for large-scale
apps (e.g., no scalability and life-cycle configurability via POA, no
Transaction Service)
- they can now interact: RMI can use IIOP, CORBA 3 can pass objects
by value, there is a remote interface to IDL compiler
1.2 The Object Managment Group (OMG)
The OMG is a non-profit orgainzation with over 800 members founded in
1989 to combine Remote Procedure Call (RPC) technology, object
orientation, and component integration and reuse in a compreheisve
framework for distributed applications. It is not a standards
body (like ISO or ANSI): it issues "specifications" (not standards).
Its specifications are typically are selected from working
"reference implementations", rather than being documents that enforce
abstract ideals, due to its industry, rather than academic,
orientation. All specifications and some tutorials are available
at www.omg.org. The OMG has issued many
specifications besides CORBA, e.g. UML, the Meta-Object Facility, and
XML Metadata Interchange for analysis and design.
organization of the OMG: p 20, adoption process: p 23-24
1.3 The Object Management Architecture (OMA)
The OMA Core Object Model defines object-oriented principles and
terminology, and the OMA Reference Model defines the system
architecture. CORBA extends and concretizes the OMA Models.
1.3.1 The Core Object Model
The OMA Core Object Model provides an abstract basis for CORBA objects.
Its primary design goals are design portability and interoperability
(any location, platform or language). It is quite abstract and
most architects and developers deal with its concrete specialization,
CORBA. (An object model was necessary as a foundation for CORBA,
and also because understanding of and agreement about object-oriented
principles and terminology were not universal at the OMG's inception.)
A component is a concrete specialization of the Core Object
Model. A profile is the Core Object Model together with
one or more components: figure p 27. For example, CORBA is a
profile that defines an interface syntax IDL for expressing the object
model, language mappings to and from that syntax, and an inter-ORB
protocol.
The Core Object Model is a classical object model that defines the
usual concepts: objects and identity , operations
(name, parameters, return values), nonobject types,
interfaces, substitutability (of implementations and of
superset interfaces, polymorphism), and inheritance (semantic
compatibility of operations with the same name and signature,
subtyping, the root class Object ). It does not
define exceptions. The CORBA Object model extends it, as
discussed below.
1.3.2 The Reference Model
The OMA Reference Model defines the basic architecture for a
distributed object system (figure p 30: note the centrality of the
ORB).
- The Object Request Broker
(ORB) is a message bus among distributed objects that provides
access to common services (directory services,
metadata, security, etc.) and location transparency (it insulates the
application from specifics of operating systems, platforms,
network protocols, etc).
- Object Services provide
fundamental, system-level functionality needed by large-scale
distributed applications (list of CORBAservices: p 32).
- Common Facilities
provide user-oriented application functionality that is not
domain-specific, e.g. the Internationalization and TIme Facilities, the
Data Interchange Facility, and the Printing Facility
- Domain Interfaces define domain-specific facilities, e.g.
there are OMG SIGs for business, telecommunications, internet, health
care,
and manufacturing (p 21-23). Several requests for information
(RFI) and requests for proposals (RFP) are in progress in various
Domain task forces.
- Application Interfaces define the functionality of
individual applications.
1.4 The CORBA object model
A servant is a programming language entity (code) that
implements an IDL interface. An object reference is an
object's identity used by clients to invoke operations, and is
opaque (users cannot access information about the object's
location, implementation, etc.). An object reference can be
incarnated by different servants over its lifetime, i.e. there is
not necessarily a one-to-one correspondence between object references
and servants. This is a major difference from RMI in which a
remote reference always denotes the same remote object, and CORBA makes
use of the mapping from object references to servants to provide
scalability options that would have to be coded with RMI. Object
references can be passed to clients or can
be converted to strings ("stringified") that can later be converted to
live
object references.
A type groups entities with a common set of operations, and are
used as parameter and return types and component
types.
Object types are related by inheritance with a root class Object.
CORBA defines several non-object types including basic
types (e.g., numeric
types, string, and Boolean), constructed types (e.g., enum
and struct), and any, a basic type
that can store a value of any CORBA type together with an indication of
the value's type.
An operation signature includes the operation name, return type
and parameter types, and an optional raises clause that
lists user-defined exceptions that execution of the operation can
signal (any operation can raise CORBA "system exceptions").
Parameter passing modes are given as in,
out or inout, like Ada parameters. The
keyword oneway indicates best-effort semantics (see
below). An operation signature can give a context
clause that lists a set of "properties" (string pairs), intended to be
like environment variables, but this feature is rarely used. An
operation invocation is often called a request .
An interface describes the operations offered by an object (in
IDL, an interface can contain operations, types and constants).
Interfaces are related by inheritance. An interface can
contains attributes, a shorthand for an accessor and modifier
operation with the given name and type.
A valuetype is a description of a set of operations, and can
also define state that is accessible to clients (like a class).
Instances are local implementations and are passed by value.
Valuetypes can inherit from other valuetypes, can implement
multiple interfaces, and can be declared abstract.
An exception is a nonobject type with a name and optional
fields, like a C structure. The standard IDL module CORBA
defines 31 system exceptions (also called "Standard
Exceptions") for network, ORB, operating system, and code
syncrhonization errors,
which can be raised by any operation (list p 180). A system
exception has a completion status (its type is an enum
of COMPLETED_YES , COMPLETED_NO , and
COMPLETED_MAYBE ), and a long minor code.
The CORBA Object Model supports three kinds of execution semantics
for requests. With at most once semantics, the operation
will execute once, unless an exception occurs, in which case it may
have executed once or not at all. With best effort
semantics (indicated in IDL by the keyword oneway ),
invocation
does not block (i.e., it is an asynchronous call) and the ORB makes its
best attempt to forward the
request. In particular, no exception is signaled if execution
of the request fails. Deferred synchronous semantics,
which is supported by the Dynamic Invocation Interface only, is like
best effort (i.e., it does not block), but the caller can poll for
results later.
1.5 The CORBA architecture
CORBA specializes the OMA Reference Model to specify the functionality
of the ORB and the details of how objects interact with it. Some
interfaces to ORB components are specified in IDL, and other components
are left to the ORB
implementor (in particular, the skeleton-ORB interface is
vendor-specific, except for Java).
CORBA architecture figure p
40: clients use IDL stubs (implicitly), DII, and the ORB interface
(e.g., to locate services);
object implementations use the Orb interface, IDL skeletons
(implicitly), DSI, and object adapters (to map object refrences to
servants).
The IDL compiler generates stub and skeleton
code which performs marshalling and unmarshalling of
parameters from the network stream to instances of the implementation
language's types in memory and vice versa. The
stub is a client proxy for a servant accessed via an object
reference, and the skeleton is a proxy for the client in
the servant. IDL stubs and skeletons are language-specific, and a
stub for one language may communicate with a skeleton in another.
The stub code is linked with the client code and the skeleton
code is linked with the object implementation, and they communicate
with the ORB run-time system to implement remote operations.
The CORBA standard defines a Dynamic Invocation Interface (DII)
that allows a client to build a request dynamically for any operation.
It provides pseudo-IDL operations with which a client can create
a request, specifying the target object, operation name, and arguments,
and then invoke the operation, giving the execution semantics, and
retrieve the return value (similarly to Java reflection). DII
makes it possible to issue requests without the client having been
linked to the corresponding stub code, e.g. to invoke operations that
were not available when the client was compiled. The Dynamic
Skeleton Interface (DSI) is used by servants to respond to such
requests via a ServerRequest psuedo-object. For
example, DSI can be used
to wrap legacy command processing code, making it available to CORBA
clients.
An Object Adapter connects a servant with the ORB. The object
adapter manages the servants' life-cycles (in particular, it activates
and deactivates servants), and selects the servant that executes a
given request. Object Adapters address the issues of server
resource management and scalability. Early versions of CORBA used
the Basic Object Adapter, which
has been deprecated because it was underspecified. Current
versions use the Portable Object Adapter (POA) interface.
Each ORB has access to an Interface Repository (IR) , a
database of run-time type information (i.e., IDL). (In fact, an
ORB can have multiple IRs and ORBs can share IRs.)
It is used by the ORB to interoperate with other ORBs, to
vaildate requests and inheritance graphs, and to streamline compiling
stubs and skeletons (because the IDL is pre-compiled). It is
accessible via IDL for clients to construct DII requests and implement
IDL browsers, and for administrators to manage distribution and
installation of interfaces. Typically, the IR is also accessible
via ORB vendor utilities.
Object Services are called CORBAservices in CORBA (list p
32). The specification for each service defines its syntax in IDL
and its semantics in English text. Defining the services in IDL
supports component reuse both "above" the interface (by standardizing
usage) and "below" the interface (by supporting different
implementations with different characteristics). It also allows
using any vendor's implementation, switching vendors, or using multiple
vendors without recoding. Implementations of the basic services
are often
packaged with an ORB. Programmers use services directly (e.g.,
Naming), indirectly via inheritance (e.g., Life Cycle),
and by building on services (e.g., Transactions). The most
fundamental services which are used in most applications are Naming and
Trading, Event and Notification, Transactions and Concurrency, and
Security. Common Facilities are called CORBAfacilities
in CORBA. Examples include the Distributed
Document Component Facilities (retired), the Internationalization and
Time Facilities, the Data Interchange and Mobile Agent Facilities, the
Printing Facility, the Meta-Object Facility (type repositories), and
the Systems Management Facility. Domain-specific Domain
CORBAfacilities are currently a very active area within the OMG
with over 20 specifications issued and many more in progress.
CORBA defines
a common format to encode object references in requests, called an
interoperable object reference (IOR) . Communication among
various ORB implementations is specified as the General Inter-ORB
Protocol (GIOP) , which defines the Common Data Representation
(CRD) and seven basic message types. The mapping of GIOP onto
TCP/IP is called the Internet Inter-ORB Protocol (IIOP) .
2. The OMG Interface Definition Language (IDL)
2.1 Introduction
The Interface Definition Language (IDL) is a strongly-typed
declarative programming-language-independent notation for defining the
interfaces of CORBA objects. An IDL interface specifies the
contract between providers and users of a service, but gives no
indication how that contract is implemented (IDL does not define any
executable statements). IDL syntax is based mostly on C++ and
includes some
features from Ada. IDL inherits some restrictions from
the languages that it must be mapped to, e.g. case insensitivity and
the lack of overloading. All IDL declarations are available
via the interface repository IDL. The
OMG IDL is now an ISO and ITU standard. IDL source files must use
the file extension .idl .
A language mapping defines the correspondence between IDL
names, modules, interfaces, types, and operations and constructs in a
particular language, and describes how to implement CORBA objects.
This includes such details as parameter passing, exception
handling, execution semantics, and access to ORB and POA functionality.
CORBA specifications define language mappings for C, C++,
Smalltalk, Ada95, COBOL, Lisp, Python, and Java, and mappings to many
other languages have been implemented (e.g., Perl, Eiffel, and
Objective-C). Note that C and COBOL are not object-oriented
languages (and COBOL does not support pointers), and that the languages
supported vary with respect to other features, e.g. parameter passing
modes, exception handling, deallocation of dynamic objects, and type
operations. Since these mappings are OMG standards, every IDL
compiler from any vendor that supports a given language must follow
them, and therefore code for that language from one IDL compiler is
compatible with that from another. (Although the skeleton-ORB
interface is vendor-specific, the interface from the object
implementation to skeleton functionality is standardized.)
2.2 Lexical analysis
IDL uses
the 7-bit ASCII character set, but string and character literals can
use the 8-bit ISO Latin-1 character set. Identifiers must begin
with a letter and are case sensitive, but may not coexist with another
identifier that differs only in case. All IDL keywords are lower
case, and an identifier that differs only in case from an IDL keyword
is an error. IDL supports the C++ preprocessor directives
#include , #define , #ifdef , and
#pragma , and
both C++ comment styles. For example, the follwing directive
includes the IDL for the Naming service:
#include <CosNaming.idl>
Declarations (but not preprocessor directives) must be followed by a
semicolon.
It is common practice to capitalize module, interface, type, and
exceptions names and to capitalize each word in a multiword identifier.
Operation, parameter, and attribute names are usually given in
lower case with the words in a multiword identifier separated by
underscore characters.
2.3 Modules and interfaces
A module defines a named scope, and modules are used to avoid
name conflicts (like Java packages and C++ namespaces). A module
can contain type, interface, and constant definitions, but not
operations or attributes. Like C++ namespaces, the contents of a
module can be defined in multiple declarations (the text refers to this
as "re-opening" the module: p 46). The standard module
CORBA declares interfaces, types and constants defined by the
CORBA standard. Each CORBAservice also define modules containing
its interfaces.
Modules can be nested (like C++ namespaces, but unlike Java packages),
but in practice nested modules usually are not used. As in C++,
the :: operator is used to specify scope paths (p 45).
That is, the full name of an interface
is Module::Interface , which must be
used to refer to the interface outside that module. The CORBA 3
IDL includes an import statement
(like import in Java or
using in C++), but most IDL compilers do not yet support it.
An interface declaration defines a type and a scope, and can
include operations, attributes, types, and constants (but not
modules). The actual object referred to by an
interface type will always be a CORBA object (servant). Like C++
but unlike Java, an IDL identifier cannot be used before it is
declared. IDL supports forward declaration of interface names,
which allows interfaces to refer to each other and permits listing the
interfaces in a module in whatever order
is sensible (p 45).
Like C++, IDL uses the : symbol to indicate interface
derivation (p 46), and multiple inheritance is supported (p 47).
Inherited identifiers cannot
be redefined in the derived interface. With multiple inheritance,
the names of the operations in each super-interface must be unique
since overloading is not supported, except for the case of operations
in a repeated ancestor (p 47). All interfaces implicitly inherit
from
CORBA::Object ( org.omg.CORBA.Object in the Java
language mapping).
It is common practice to list all the types, exceptions, and constants
within a module at the beginning of the module, followed by the
interface
definitions, which include operations and attributes only, rather than
to define types within interfaces.
2.4 Non-object types and constants
IDL defines three kinds of types: basic, constructed, and template
types. The basic types are [unsigned] short
, [unsigned] long , [unsigned] long long
, float , double , long double
, char , wchar , string ,
wstring , octet , and boolean (p
48-49). The sizes of numeric types are specified to allow
unambiguous marshalling and interoperability.
The template types are unconstructed types that require
parameterization, and are fixed , string ,
wstring , and sequence . As in C,
the typedef statement is used to create type aliases,
and is used to name specifications of template types. A bounded
string type is defined with a typedef that uses the C++
template parameter notation to give the size (p 49: NOTE the examples
on page 49 in the text are backwards: the type specification must
preceed the type alias). Similarly, a fixed point type is defined
with a typedef containing a template with parameters
that give the number of decimal digits and the scale (p 50).
A sequence is an ordered list of items of the same type, and a
sequence type can be bounded or not. A sequence type is defined
with a typedef with a template parameter that gives the
element type and an optional parameter that gives the size, and
sequences of sequences can be defined (p 51). (Bounded sequences
are rarely used.) Array types are defined using a typedef
with the number of elements given in square brackets, and
multidimensional arrays are supported (p 52). Since arrays are
fixed-length, they are rarely used in interface definitions.
Currently, IDL supports the use of anonymous types, e.g.
sequence<int> , as parameter or return types or as the
type of a structure, union, or valuetype member. However, this
usage is deprecated because it causes problems for some of the language
mappings, and will be removed in a future IDL version. Therefore,
you should always use a typedef for template types that
will be used as parameter, return or member types.
The constructed types are enum , struct
, union , exception , and
valuetype . An enumerated type enum type).
Structure types are defined as in C++ (p
50), and do not support inheritance, operations, or information hiding
(i.e., all fields are public). Unlike C++, unions
are defined with a discriminator, using a syntax similar to the C
switch statement (p 50). Exception types are declared with
the same syntax as structure types (p
52), and do not support inheritance and operations.
IDL supports forward declaration of constructed types, e.g.
struct Point; , which allows a type to be used as a operation
parameter type or a sequence element type before its complete
declaration appears. The type must be defined in the same file in
which the forward declaration occurs.
any is a basic type that can store a value of any CORBA
type (including basic types), and an instance contains information
about both the type (via a TypeCode constant) and the
value. Though IDL defines the keyword as a basic type, it does
not define the operations for checking the type or accessing and
setting the value in an instance. Instead, the actual
representation of an
instance and the operations available are defined in each language
mapping. For example in
C, an instance is mapped to an instance of the structure
CORBA_any , which contains a type code member and
a void* member pointing to the value (p 83).
To access the value, the programmer checks the type code and then
casts the pointer. To set the value, the programmer sets both
members.
IDL supports constants whose type is a basic type, enumeration type, or
an alias of a basic or enumerated type. Constants are defined
using the
const keyword and the = operator (p
52-53). Like the convention in C++ and Java, constant names
are usually all capitals with underscores separating the words in a
multiword identifier. Literal values are written using the C
literal notation and may be expressions using
C operators. Fixed-point literals are identified by a trailing
d or D.
2.5 Operations and attributes
Operation declarations appear similar to C++ member function prototypes
(except that parameter names are required), and may have a
raises clause specifying a comma-separated list of user-defined
exceptions enclosed in parentheses and a context clause.
As in C++, void is used as the return type of an
operation that does not return a value. As discussed in the
previous section, parameter and return types should be named, not
anonymous, types. Rather than using parameter passing modes
(e.g., & for pass by reference in C++), each
parameter must have a directional indicator in ,
out , or inout , as in Ada (p 53).
Arguments of primitive types, enumerated types, structure types
and union types are passed by value. Note that this means that it
is not possible to pass or return a null value (e.g., for a structure
or a string) because pass by value always copies a value. Object
type (i.e., interface) arguments are passed as opaque object
references. As discussed in the next section, CORBA has recently
added the
type valuetype to support passing instances
of object types by value and passing null values.
If an operation declaration is preceeded with the keyword oneway
, invocations uses best-effort semantics and are asynchronous.
Such an operation must return void , cannot have
out or inout parameters, and cannot raise
exceptions (p 54).
An attribute declaration is a shorthand for declaring an
accesor and modifier operation (p 54). If the attribute is
declared readonly ,
only the accessor is present. Although it appears like field
definition, an attribute is not necessarily implemented by a state
variable. Attributes cannot declare user-defined exceptions, but
an invocation of an attribute operation can raise a system exception.
A recent extension to IDL allows specifying exceptions for
attributes with get_raises and set_raises
clauses as follows:
attribute Type attrName get_raises (...) set_raises
(...);
The names of the generated
accesor and modifier operations for an attribute depend on the
language mapping.
2.6 Valuetypes
Valuetypes were introduced in CORBA 2.3 to address two issues having to
do with
CORBA parameter passing:
- Class instances cannot be passed or returned by value
- Null values cannot be passed for constructed types, sequences, or
string parameters or return values
Before the introduction of valuetypes, it was not possible to pass an
object (i.e., an instance of a class rather than a structure) by
value. This capability is necessary for simple objects such as
Rectangle , Date and Currency ,
which are defined as
classes rather than structures so that they can provide encapsulation,
information hiding, and polymorphism. (IDL structures are passed
by value, but cannot include operations or private fields, and cannot
use inheritance and polymorphism.) We do not want to treat such
objects as remote services and we want local invocation semantics for
their
methods. Valuetypes provide
this capability: instances are passed by value and operations on a
valuetype are local operations on that process's copy. The
marshalling and unmarshalling of valuetypes transmits the object's
state variables and is guaranteed to preserve shared and circular
references to valuetypes, e.g. to pass data structures.
Valuetypes are not a subtypes
of CORBA::Object , but have their
own base type ValueBase . Valuetypes are a
relatively recent addition to CORBA, and might only be
supported by ORBs for Java and C++. A major motivation for their
introduction was to permit interoperability between CORBA
and RMI-IIOP.
With support for valuetypes, the developer has a choice between
using an interface and a valuetype for a class. A valuetype
should be used for classes such as Date and Currency
whose instances are "anonymous" values that are treated
in the same way as numbers or strings, whereas an interface should be
used for objects that represent a domain object that has an identity.
For example, a valuetype should not be used for an Account
class: there should be one instance (on a server) that represents an
individual account and maintains its state, rather than there being
copies
in various processes. Operations that modify the object such as
deposit must be executed in one place where the object exists so
that their effects are visible to all
users of the object, rather than being performed on a local copy.
"Concrete" (versus abstract) valuetypes are defined similarly to
interfaces, but can contain private or public
"state variables" (fields) and "initializers" (like constructors)
declared with the factory keyword (p 55). The
state variables are declared in the same manner as those in a
structure. Initializers may only have in
parameters, and no default initializer is provided if none are declared
(unlike Java and C++ which supply a default constructor in this
case). In fact, a valuetype definition appears like a class
definition, and language mappings for object-oriented languages map
valuetypes to classes. Once
valuetypes are widely supported, they may replace structures in many
object-oriented CORBA applications. IDL supports forward
declaration of valuetypes.
The following example illustrates using valuetypes for data structures:
module Tree {
typedef sequence<string> StringList;
valuetype BinaryTree {
private string name;
private BinaryTree left;
private BinaryTree right;
factory init(in string name);
StringList pre_order();
StringList post_order();
boolean equals(in BinaryTree tree);
// ... other operations ...
};
};
The operations in a valuetype are local operations implemented in a
language-dependent manner. State members whose types are
valuetypes (like left and right above)
use local reference semantics, like Java class-type variables.
Similarly, when a valuetype instance is passed to a local
operation, it uses local reference semantics. However, when
passed to an operation whose target is an object reference, the
valuetype instance is passed by value: passing the root of a
BinaryTree passes the entire tree, and within the server
implementation, accessing the descendants is a local operation.
The IDL compiler generates marshalling code for a valuetype
unless the
custom keyword is given, in which case
the programmer must supply language-specific marshalling code (p 55).
Valuetypes can inherit from other valuetypes using the :
notation (p 57). A valuetype can inherit operations from an
interface listed after the keyword supports (p 55).
However, invoking those operations on a valuetype instance is a
local operation. As with Java or C++ classes, initializers are
not inherited. An abstract
valuetype is declared with the
abstract keyword, and cannot declare state members or
initializers (p 56). (An abstract value type is analogous to a
Java interface, not a Java abstract class.) An abstract valuetype
differs
from an interface in that its implementations are local objects and
operation invocations are local. A valuetype can inherit from any
number of interfaces or abstract value types, but can have no more than
one concrete valuetype ancestor. If a valuetype supports an
interface, an instance can become a
CORBA object by using the mechanism defined in the language mapping
(e.g., extending a class generated by the IDL compiler) and being
registered with the ORB via an object adapter. In this case, if a
parameter or return type refers to that object via the interface
type, it is passed by remote reference like any CORBA object.
That is, the parameter type determines whether the request uses
pass
by value (valuetype) or pass by object reference (interface).
It is possible that an instance of a valuetype is passed to a machine
that does not have the code that implements the actual
type, e.g. if an argument's type is a subtype of an operation's
parameter type, or whose ORB does not have a registered factory for the
valuetype (discussed below). The recipient attempts to
dynamically load the implementation (locally for C++, possibly remotely
for Java). If this is not possible, it attempts to create an
instance of the parameter type, which will be a supertype of the
object's type, using the field values from the argument. This is
only possible if those fields have the same meaning in the object's
type that they do in the parameter
type. The programmer can declare that this is possible by using
the truncatable keyword with the supertype specification
(p 57). If the valuetype's type does not declare the supertype as
truncatable and its implementation is not available, a
NO_IMPLEMENT exception is raised.
An "abstract
interface" is declared with the abstract keyword, and
can have both interfaces and valuetypes
as subtypes (p 57-58). This allows declaring a
parameter type whose corresponding argument can be either a valuetype
or a CORBA object. Abstract interfaces are not subtypes of
CORBA::Object , and may only inherit from abstract interfaces.
Since non-interface parameters and return values are passed by
value, it is not possible to pass or return a null value for a
structure or sequence (like a variable in C++ which is not a pointer).
A boxed valuetype, also
called a value box, is a
valuetype
with a single, unnamed state member, and support passing or return null
values. The state member may be any IDL type except for
valuetypes. Syntactially, boxed valuetype appears like a
typedef (p 56). The module CORBA includes the declaration
valuetype StringValue string ;.
3. CORBA in Java
3.1 A basic CORBA program
We present the basic CORBA development process in 5 steps. These
are quite similar to the steps in the process for RMI, with writing the
IDL rather than writing the remote interfaces, and compiling the IDL
with idlj rather than generating stubs with rmic.
Of course, the details of writing the classes and server and client
processes are different with CORBA. Chapter 4 in the text gives
two versions of a simple CORBA program. Both versions provide a
single operation hello that returns a message to the
client, the first with no parameters (implementation p 156), and the
second with out parameters for the message time
(implementation p 163).
1) Write the IDL (p 145, 159: nesting a series of modules to obtain a
multipart Java package name is rarely done)
2) Compile the IDL (p 145)
to generate interfaces and classes to use and extend
(p 146, typo: should be _GoodDayStub.java, i.e. with a
leading underscore). JDK
1.4 contains a program idlj that generates Java from IDL
(the idltojava program from JDK 1.2 is out of
date). Note that it is necessary to use the -fall
option to obtain all of these interfaces and classes (the default is -fclient,
which does not generate the skeleton classes).
For the interface Intf, the IDL compiler generates:
- the operations interface
IntfOperations Intf which extends
IntfOperations
- an
IntfHolder class with a public field value
to use for out parameters
- an
IntfHelper class that defines class operations
associated with the type
(primarily narrow)
- a
_IntfStub class for the client stub
- an
IntfPOA abstract skeleton class for the server
implementation to extend, and an optional IntfPOATie for
the server implementation to delegate to via the tie mechanism
3) Write the client application:
- import
org.omg.CORBA.*
- call
ORB.init to initialize the ORB and get a
reference to the ORB pseudo-object (p 148: the second argument is a
properties file with ORB properties)
- obtain object references (p 148-149: get a stringified
interoperable object reference from the command line, "narrow" it to
convert it to the correct type, and
check for null; alternatively, obtain the naming service via
orb.resolve_initial_references and resolve the object name)
- invoke the operation (p 149, p 161 with
out
parameters and holders)
- all CORBA System Exceptions are descendants of
SystemException,
which is unchecked, but a robust application will
catch and handle them rather than exiting (p 149)
- call
orb.shutdown(true) (where true
indicates that the call should block until all pending requests and POA
operations have completed) and orb.destroy() before
terminating
4) Write the servant implementation class:
- by convention, the servant
class that implements the IDL interface
Intf is named
IntfImpl
- either extend the generated POA skeleton
class or delegate via the tie mechanism (discussed below)
- define the constructors, variables, and methods (p
155-156, p 164 with
out parameters)
If the servant class is handled by a
POA other than the root POA (e.g., because there are different policies
for different servants), the servant constructor takes the POA
used to activate the object, and the servant class overrides
_default_POA() to return that POA (the default
implementation returns the root POA).
5) Write the server main program (p 156-158, p 165):
- initialize the ORB and create a servant
- obtain a POA (
orb.resolve_initial_references
provides access to the root POA, the interface repository, and
CORBAservices)
- activate the servant to enter it in the POA's Active Object Map:
use
poa.servant_to_reference (p 157) or
poa.activate_object (which
returns a byte[] object ID that can be converted to a
reference with poa.id_to_reference )
- activate the POA manager to enable dispatching requests to
servants
- export the object reference by printing a stringified IOR for
clients to use (or write it to a file); alternatively, bind the
object reference in a naming service
- call
orb.run to wait for requests
- handle exceptions
- call
orb.destroy() before terminating (run
blocks until the ORB is shut down by another thread)
3.2 The IDL to Java mapping
3.2.1 Identifiers, basic types, type aliases, and constants
Generally, IDL identifiers are mapped to Java identifiers unchanged.
IDL identifiers that clash with Java keywords are mapped to a
Java identifier that
begins with an underscore. For example, an IDL operation named
continue is mapped to a Java method called _continue
. Some IDL identifiers, primarliy type names, are mapped to
several identifiers, each of which is the original identifier with an
additional suffix. For example, a structure Rectangle
is mapped to the classes Rectangle ,
RectangleHolder , and RectangleHelper .
Java mapping for basic data types: table p 168.
DATA_CONVERSION is raised if a Java character is outside the
8-bit IDL character range. The large values for an IDL unsigned
numeric
type that are not within the range of the corresponding Java type must
be handled by the programmer. The Java mapping does not specify a
Java type corresponding to the IDL type long
double .
The IDL any type is mapped to the class
org.omg.CORBA.Any , which defines an accessor and modifier for
the type code, extraction and insertion methods for all non-object
types and for org.omg.CORBA.Object , and marshalling
operations (p 184-187). The methods that handle insertion and
extraction of Object s use the corresponding class's
helper class's insert and extract methods.
Java does not support type aliases
so appearances of type aliases created with the IDL
typedef use the original type in the Java langauge mapping.
An IDL constant within an interface
is mapped to a public static final variable in the corresponding Java
operations interface (p 210 typo: the constant should be in the
operations interface). Since Java constants must be be defined
within a class or interface, IDL constants defined at module scope are
mapped to an
interface whose name is that of the constant which contains a public
static final variable named value which is initialized
with the given constant value (p 210-211).
3.2.2 Holder and helper classes
The Java language mapping defines a holder class for each IDL
type and interface, which is used as the parameter type of Java methods
that
correspond to IDL operations with out or inout
parameters. For each basic IDL type, the
package org.omg.CORBA includes a holder class with a
public value field (p 170), a no-argument constructor and
a constructor that takes the wrapped value. For each user-defined
interface, the IDL compiler generates a holder class whose name is the
type name with Holder appended (p 171). In
addition to the constructors and public field, the holder
class for an IDL interface defines the marshalling methods
_read and _write and the
type code accessor _type , whose methods are delegated
to the corresponding helper class value field for an inout parameter), and
then access its value field
after the request has executed (p 161). Servant implementations
set or access the value field (p 164). Holder
classes are subclasses of the class
org.omg.CORBA.portable.Streamable
(discussed below).
For each user-defined interface, the IDL compiler generates a
helper class whose name is the type name with the suffix Helper
appended. The class defines class methods for "narrowing" object
references (i.e.,
"checked downcasting"), inserting a value into an any
and extracting a value from an any , marshalling and
unmarshalling values to and from a stream, and returning an ID and a TypeCode
(p 171).
Developers should always use the
narrow method rather than a Java cast to cast an
object reference to a sub-interface type because it creates a
stub object of the right type if necessary. In addition, it is
possible that the local ORB does not have the necessary information in
its Interface Repository and must contact another ORB to verify the
cast. If the argument is not of the right type, narrow
signals org.omg.CORBA.BAD_PARAM (which, unfortunately,
is unchecked). The helper class is a separate class to accomodate the
Java-to-IDL mapping.
3.2.3 Constructed and sequence types
The Java classes to which IDL types are mapped all extend
org.omg.CORBA.portable.IDLEntity , a marker interface that
extends java.io.Serializable . This interface marks
implementing classes as being generated from an IDL type that has a
corresponding helper class. RMI IIOP serialization looks for this
marker to perform marshalling and unmarshalling.
An IDL enumeration is mapped to a Java class that extends
IDLEntity and
defines (p 173):
- class constants for the enumeration values and for their
corresponding
int values
- a protected constructor
- a
method
value to obtain the int
- a
class method
from_int that returns the enumeration value
corresponding to the
argument int
Although no equals
method is defined, the IDL to Java Language Mapping Specification
states that all instances of the class
will be mapped to one of the defined class constants, so the default
implementation of equals suffices. The
IDL compiler also generates holder and helper classes for each
enumeration (p 173-174).
An IDL structure is mapped
to a final Java class that extends IDLEntity and defines
(p 174):
- public fields for each member
- a no-argument constructor and a
constructor that takes values for each member
Unfortunately, the class does not define equals,
clone, or toString . Holder and helper
classes are
generated for each structure.
An IDL union is mapped to a final Java class that extends
IDLEntity and defines (p 175-176):
- private fields for the discriminator and
the contained value
- a no-argument constructor
- an accessor for the
discriminator
- accessors and modfiers for each possible value
The value accessors and modifiers have the same names as the
corresponding fields in the union. The accessors raises
BAD_OPERATION if the
discriminator is not set to its corresponding value, and the modifiers
set the discriminator appropriately. Holder
and helper classes are generated for each union.
CORBA System Exceptions are all mapped to subclasses of
org.omg.CORBA.SystemException , a subclass of
RuntimeException , and are unchecked (list p 180). These
exceptions are raised by the ORB implementation and are rarely raised
by application code. Since CORBA System Exceptions are unchecked,
the Java interface methods do not declare them in their exception
specifications, but handling these exceptions is not enforced by the
compiler. Therefore, an unhandled System Exception could occur,
which would cause the program to exit. All IDL exceptions are
subclasses of
org.omg.CORBA.UserException (p 177), a subclass of
Exception , and are checked (p 178). An IDL exception is
mapped
to a final Java class that defines (p 178-179):
- a public field for each member
- a no-argument constructor that sets the message to the
exception's repository ID
- a constructor that takes values for each
member
- a constructor that takes values for each member and a
string
message
Holder and helper classes are generated for
each exception.
When an IDL sequence type appears as a parameter, return or member
type, it is mapped to a Java array type whose element type is the same
as the sequence template parameter type. That is, no class is
generated and Java collection classes are not used. Holder and
helper classes whose names are based on the alias name are generated
for each typedef of a sequence (p 183-184). The
package org.omg.CORBA includes holder and helper classes
for sequences of each basic type, e.g. DoubleSeqHolder
and DoubleSeqHelper. IDL arrays are mapped to
Java arrays, and holder and helper classes are generated (p 181).
Bounds checking is done in the marshalling methods of the helper
class (p 181-182).
3.2.4 Modules
An IDL module is mapped to a Java package with the same name.
Nested modules are mapped to packages with multipart names that
reflect the module nesting. (Multipart package names in Java are
sometimes called "subpackages" even though the scope of package
a.b is not nested within the scope of package a
.) With nested modules, the IDL compiler generates the source
code in a directory structure that matches the multipart package names,
as is customary for Java source code.
3.2.5 Valuetypes
A concrete valuetype is mapped to a
Java abstract class that extends
org.omg.CORBA.portable.StreamableValue (or CustomValue
if the valuetype defines custom marshalling) which has the same fields
as the value type and abstract methods for each operation.
Private fields are mapped to protected fields in the Java class
and public fields are mapped to public fields. The Java class
also defines the StreamableValue methods _type
, _read , _write , and
_truncatable_ids , the last of which returns the repository IDs
of classes to which instances can be truncated (p 188-189). When
a valuetype
inherits from another valuetype, its mapped Java class extends the
mapped Java class of
its supertype, and declares only the fields and methods in its IDL
definition.
The
IDL compiler generates a factory interface for each valuetype whose
name is the valuetype name with ValueFactory
appended. It implements
org.omg.CORBA.portable.ValueFactory and contains a
method for each initializer in the valuetype (p 189). The
developer implements this interface, including the ValueFactory
method read_value. The developer must
also register the implementation class with the ORB so that the ORB can
marshall instances of the valuetype via org.omg.CORBA_2_3.ORB.registerValueFactory,
which takes the value factory implementation and the repository ID for
the value type (p 267). Note that the ORB included with JDK 1.4
does not support this operation.
The
IDL compiler also generates holder
and helper classes for each valuetype. The
helper class for a valuetype also has a method for each factory
interface method that takes additional org.omg.CORBA.ORB
argument, which is used to access the implementation of the factory
interface registered with the ORB (p 190).
An abstract valuetype is mapped to a Java interface that extends
org.omg.CORBA.portable.ValueBase, and holder and helper
classes. The mapped Java class for a
valuetype that inherits from an abstract valuetype implements the
abstract valuetype's mapped interface.
A value box that contains a primitive type is mapped to a class that
extends org.omg.CORBA.portable.ValueBase with a single
public field called value and a constructor that takes a
value for the field (similar to a holder class: p 191). No class
is generated for a value box that contains a type that maps to a Java
class (e.g., a valuebox for an IDL structure): each use of the value
box is mapped to that class. The
helper class for a value box extends org.omg.CORBA.portable.BoxedValueHelper
, and also defines its marshalling methods read_value
and write_value (p 192).
3.2.6 Generated interfaces and classes
The following figure illustrates the hierarchy of the operations and
signature interfaces and the stub and skeleton classes generated by the
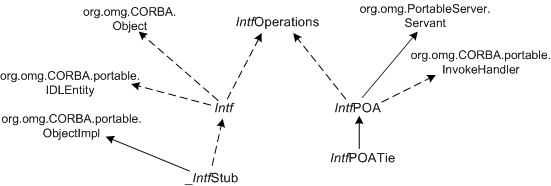
IDL compiler for the interface Intf:
As stated above, an IDL interface
Intf is mapped to two
Java interfaces, the
operations interface IntfOperations
and the
signature interface Intf
which extends
IntfOperations,
org.omg.CORBA.Object, and
org.omg.CORBA.portable.IDLEntity
. The operations interface is not a subclass of
org.omg.CORBA.Object (the supertype of all CORBA remote
references) and is implemented by the skeleton class IntfPOA
which is (typically) extended by the servant implementation class.
Clients use the signature interface, which is extended by the
stub class, as the type of object references. Holder and helper
classes
are also generated. Inheritance among IDL interfaces is mirrored
by inheritance among both the operations and signature interfaces: if
the IDL interface Derived inherits from Base,
the Java interface DerivedOperations inherits from
BaseOperations, and the Java interface Derived
inherits from Base and DerivedOperations.
For an interface Intf, the IDL compiler generates a stub
class _IntfStub
that implements the signature interface
and extends
org.omg.CORBA.portable.ObjectImpl. ObjectImpl
(discussed below) is the standard
implementation of the org.omg.CORBA.Object interface, so
the stub class represents a CORBA object.
As with RMI, the stub class is not used directly in client
code but its compiled bytecodes must be distributed to client
processes. If Intf
has multiple base interfaces, the stub implements all the corresponding
signature interfaces and
code is generated to implement the operations in each interface.
However, this procedure generates the same method code in every stub
class whose IDL interface derives from the IDL interface in which the
corresponding operation is defined. Therefore, the IDL to Java
mapping specification permits inheritance among stub classes to reduce
the code size. However if an IDL interface derives from more than
one interface, the stub class can have only one stub superclass, so it
may use delegation for the operations in the other interfaces (p
220-221).
The IDL compiler also generates an abstract skeleton class
IntfPOA (the POA suffix indicates that the
skeleton is used with a POA)
that implements the operations interface and extends
org.omg.PortableServer.Servant and implements org.omg.CORBA.portable.InvokeHandler
(discussed below). If Intf
has multiple base
interfaces, the skeleton class implements all the corresponding
operations interfaces (p 219-220). An IDL compiler can also
generate the "tie" class IntfPOATie
which is a subclass
of IntfPOA .
As discussed in the next section, the
servant implementation can either extend the generated POA skeleton
class or the tie class can delegate operations in the operations
interface to the servant implementation.
Operations are mapped to methods with
the same names in the operations interface. The type
of an in parameter or a return type is the
corresponding Java type defined by the language mapping, while the type
of an out or inout parameter
is the holder for the corresponding Java type. The operation's
raises clause is mapped to an exception specification that lists
the corresponding exceptions (p 213).
Attributes are mapped to methods with the same name as
the attribute in the operations interface. The accessor returns
the attribute type and if the attribute is not read-only, the
modifier takes the attribute type (p 211). Note that the
JavaBeans naming conventions getAttr and setAttr
are not used for attributes.
Java does not permit defining non-static
classes within interfaces. When an IDL type such as
a structure or exception is defined within an interface
Intf, the language
mapping generates a package called
IntfPackage nested
within the package corresponding to Intf's
module and places the mapped classes
for the IDL type within that package.
3.2.7 The tie mechanism
(Note: see sections 5.14.4.1 and 9.4 in
the text.) As stated above, the servant implementation
class typically extends the generated POA skeleton class,
which implements the operations interface. However, suppose
the IDL interface Derived extends the IDL interface Base
. Since DerivedImpl extends DerivedPOA
, it cannot extend BaseImpl so all methods and fields in
BaseImpl have to be restated in DerivedImpl,
which is clearly a problem for further development and maintenance.
To allow inheritance among servant implementation classes, CORBA
provides the tie mechanism which uses delegation instead of
inheritance to attach the servant to the skeleton. This
mechanism is also useful when the IDL interface that a servant class
implements derives from more than one IDL interface because
the servant cannot be a subclass of more than one skeleton class, or if
the
servant implementation must extend another application class.
The IntfPOATie class is
a subclass of IntfPOA that delegates
all methods in the operations interface to a delegate that implements
that interface, which will be the servant implementation (p 208, 384:
typo the _poa field is not used).
The object to which the tie class delegates is given as its constructor
argument. To use delegation, the servant class implements the
operations
interface and may extend whatever class is necessary. The server
program creates an instance of the servant class and passes it to the
constructor for the tie class so that the tie class delegates methods
in the operations interface to the servant object. Finally, the
tie class rather than the servant class is exported to the POA because
the tie class, not the servant class, is a descendant of Servant
(p 383).
A servant can be the delegate for any number of tie objects.
3.2.8 Portability interfaces
CORBA does not specify the interface between the ORB run-time system
and the stub and skeleton code. However, Java users expect to be
able to load code dynamically, and do not expect to recompile stubs
when loading them to a process that uses a different vendor's
ORB. The Java ORB Portability Interfaces org.omg.CORBA.portable
and org.omg.PortableServer .
The class ObjectImpl, which is the superclass of all stub
implementations, (p 198) implements org.omg.CORBA.Object
by delegating its methods to the abstract class
org.omg.CORBA.portable.Delegate (p 199-200), which each ORB
vendor extends. Similarly, the abstract class
org.omg.CORBA.PortableServant.Servant , which is the superclass
of all skeleton classes (and therefore all servant implementations),
delegates its methods to Delegate . That is, the
ORB vendor provides the functionality needed by stubs and skeletons by
defining a concrete subclass of Delegate .
Marshalling is
defined in terms of the classes
org.omg.CORBA.portable.InputStream (p 202-203),
OutputStream (p
204-205), and Streamable (which is implemented
by holder classes). Alternatively, the skeleton and stub
classes can use DII and DSI rather than portable streams (p 216-218).
Each stub class extends ObjectImpl and implements the
corresponding signature interface (p 206). The stub class
implements each method in the signature interface using methods in
ObjectImpl (that delegate to the vendor's Delegate
implementation) and portable streams (p 214-5). Each skeleton
class extends org.omg.PortableServer.Servant and
implements the corresponding operations interface (which is not a
subclass of org.omg.CORBA.Object )
org.omg.CORBA.portable.InvokeHandler (p 207).
InvokeHandler defines
a single method invoke that invokes the given method
using portable streams for the parameters and return value.
3.2.9 The Java to IDL mapping
The OMG has also specified a mapping from Java to IDL which allows
existing Java RMI-IIOP applications (especially EJB applications) to
interoperate with CORBA applications.
It deals with issues such as Java identifiers that are
IDL keywords, overloaded method names, Java's Unicode strings, Java
classes, etc. We will not cover this mapping in detail.
4. The ORB Run-Time System
4.1 Pseudo-IDL and local interfaces
CORBA uses IDL to define a number of interfaces that specify
functionality provided by the ORB so that there is an unambiguous
language-independent specification of the operations and their
parameter types, return types, and exceptions. These interfaces
are designated as pseudo-IDL (PIDL), which means that the
interfaces do not inherit from CORBA::Object and their
implementations, which are referred to as pseudo-objects , are
not CORBA objects. These objects are "pseudo" in the sense that
the ORB supplies the object that implements the operations and
invocations are local.
Pseudo-objects cannot be passed as parameters to remote
invocations, cannot be stringified, cannot be accessed via DII,
and their interfaces are not in the Interface Repository. For
example, the ORB and Object interfaces and
the interfaces used with DII are designated as PIDL.
The CORBA specification is moving away from the use of PIDL.
Together with the CORBA Component Model, CORBA 3 introduces the
keyword local for local (i.e.,
non-remote) interfaces defined in IDL. Interfaces that are
not local are called "unconstrained". The special rules for local
interfaces are:
- A local interface may inherit from other local or unconstrained
interfaces, but an unconstrained interface may not inherit from
a local interface. A valuetype may support a local interface.
- A local interface is a "local type", as is any non-interface type
declaration constructed using a local interface or other local
type.
For example, a struct, union, or exception with a member that is a
local interface is also itself a local type. A local type may be
used as a parameter, attribute, return type, or exception declaration
of a local interface or a valuetype. A local type may not appear
as a parameter, attribute, return type, or exception declaration of an
unconstrained
interface or as a state member of a valuetype.
Local interfaces are mapped to language constructs according to the
standard mapping for the language, but references cannot be passed to
remote operations or stringified: they are only valid within the local
process. Furthermore, local interfaces are not entered into the
Interface Repository and their operations
cannot be invoked via DII, and they cannot define oneway
operations.
Each language mapping must specify how programmers access the
functionality provided by the ORB. In the Java language mapping,
there are a number of abstract classes in the package
org.omg.CORBA that provide the operations of each PIDL interface
such as ORB , Object , Request
, TypeCode , and NamedValue . There
are no holder or
helper classes for these classes. The PIDL interfaces defined
for the POA architecture such as POA , POAManager
, Servant , and the various policy constants
are defined in the module PortableServer and are mapped
to interfaces and classes in the package org.omg.PortableServer
. Since these interfaces are local, they are mapped to operations
and signature interfaces and helper classes in that package, but there
are no holder classes since they cannot be marshalled.
4.2 The Object interface
(Note: see sections 2.3.5.2 and 6.1 in the text.) The PIDL
interface
CORBA::Object (p 60) defines operations available for all object
references. However, these operations are not remote operations
executed by a servant, but are performed by the ORB. For example,
get_interface is a local call into the ORB's Interface
Repository, not a remote call on the object reference that invokes a
servant method. This interface is mapped to the interface
org.omg.CORBA.Object in Java, in which each method name is
preceeded with an underscore.
get_interface returns an InterfaceDef object
from the ORB's interface repository that represents the object's
interface, which can be used to access type information, usually as the
basis for DII. In the Java language mapping,
_get_interface_def returns org.omg.CORBA.Object .
is_a returns true if the argument Interface Repository
identifier refers to a type that is equal to or an ancestor of the
object's type, or false otherwise. Performing the operation may
require the local ORB to contact a remote ORB or
Interface Repository. If this fails, an exception is signaled.
is_nil returns true if the object reference refers to
OBJECT_NIL or returns false if it refers to an object.
Equivalently, Java programmers may test
objectRef == null .
non_existent returns true if the object implementation
(the servant, not the reference) does not exist, and false if it exists
or the ORB cannot confirm whether the object exists.
is_equivalent returns true if the object
reference refers to the same CORBA object as the argument object
reference, and false if they do not or equivalence cannot be
determined. (Do not compare stringified object references to
determine equivalence.) is_equivalent and
non_existent are not intended for applications, but for
infrastructure components that manage (and wrap) object references and
might wish to deallocate resources when possible.
hash returns an object's hash value, e.g. to use in a hash
table. As with most hash functions, if two object references
return different hash values, they do not refer to the same object, but
the converse is not true.
duplicate and release support
programmer-controlled memory management, and are rarely used by
programmers. (For example, the C++ language mapping supplies a
smart pointer type for each object reference
that uses these methods in its copy constructor, assignment operator,
and destructor.) duplicate is necessary because
object references are opaque and represented in an ORB-dependent way,
so programmers cannot create instances directly. The stub keeps a
reference count to determine when the object reference's memory can be
deallocated. If the object reference
is copied to another local object or thread (e.g., by pass
by value), this reference count becomes inaccurate (p 61).
duplicate increments the reference count and must
be called when creating a copy of the reference. Similarly,
release must be called when an object reference goes out of
scope (p 62). Note that these operations do not duplicate or
release any servant.
create_request (p 259) is used to begin the
process of building a DII request.
The methods get_policy,
get_client_policy , get_policy_overrides
, set_policy_overrides , validate_connection
, and get_domain_managers access
and manipulate POA policy information (discussed in section 4.4 below).
The CORBA 3 specification describes a type
CORBA::LocalObject derived from CORBA::Object
which is the superclass of all local interfaces. However,
it states that its operations are defined by each language mapping
rather than giving IDL for the type. The specification does
state that inherited operations such as get_interface
, get_policy and create_request signal
the NO_IMPLEMENT system exception, that
non_existent always returns false, that is_equivalent
returns true if the argument is the same local implementation
as the target, and that marshalling or stringifying a local
implementation
signals the MARSHALL system exception.
4.3 The ORB interface
(Note: see sections 2.3.5.1, 2.3.5.3, 6.2
and 6.8 in the text.) The PIDL interface CORBA::ORB
defines operations that support ORB functionality that does not depend
on the object adapter being used. Operations are provided for:
- ORB initialization
- obtaining initial references (e.g., to services)
- converting object references to strings and back
- starting and stoping the ORB, and emulating concurrency
- creating
anys, type codes, and other pseudo-objects
used with DII
- sending multiple DII messages, and accessing the result of a
deferred synchronous invocation
- managing value factories
- creating policy objects
As with CORBA::Object, the operations are not remote
invocations. This interface is mapped to the abstract class
org.omg.CORBA.ORB in
Java, and is used by both servers and clients.
The module CORBA provides a free-standing
(non-encapsulated) PIDL operation ORB_init that
initializes
the ORB and returns a reference to it (i.e., it is not defined in the ORB
interface). The arguments are a sequence of strings that give an
environment and the ORB's name (p 66). The Java language mapping
provides three overloadings of the class method ORB.init
(p 233). The no-argument version returns a "singleton" ORB that
acts only as an Any and TypeCode factory.
By default, calling ORB.init with arguments
returns the Java IDL ORB implementation. To start a different
ORB, pass a properties object to ORB.init in which the
property org.omg.CORBA.ORBClass is set to the ORB
implementation class name. The property
org.omg.CORBA.ORBSingletonClass can be set to the name of the
class to be returned by the no-argument ORB.init .
The operation list_initial_services returns a sequence of
strings identifying the services and facilities supported by the ORB
(e.g., "InterfaceRepository" , "RootPOA" ,
and "NameService" ). The operation resolve_initial_references
takes one such string and returns an object reference for that service,
which must be narrowed to the correct type using its helper class (p
66, 234). It may signal the IDL exception
CORBA::ORB::InvalidName , which is mapped to
org.omg.CORBA.ORBPackage.InvalidName in Java. The method get_service_information
can also be used to obtain information about services and facilities
supported by the ORB (see the specification for details).
Object references are opaque and their implementation may differ among
ORBs so it is not possible to store an object reference directly.
This
capability is provides by stringified object references, often
called "stringified IORs" because the format is derived from the
Interoperable Object Reference format used by GIOP. A
stringified object reference is obtained by passing an object reference
to ORB::object_to_string , and that object reference can
be recreated using ORB::string_to_object , whose result
must be narrowed (p 234). This feature allows storing object
references in files, Emailing object references, posting object
references on the web, etc.
The operation run allocates the
system resources necessary to start the main ORB thread and
starts it (p 237). It blocks until another thread calls
shutdown , which deactivates all servants and destroys all
object adapters, and then stops the ORB. The boolean argument to shutdown
indicates whether to wait until
all pending object adapter operations have finished before shutting
down. If a thread that is performing an invocation were to
call orb.shutdown(true) , a deadlock would occur, so
doing so signals the exception BAD_INV_ORDER . The
operation destroy releases the ORB's resources, shutting
down the ORB first if this has not been done. The operations
work_pending and perform_work are provided to
multiplex the main thread to provide concurrency for languages that do
not support threads (see the specification for details).
When the ORB must create a valuetype instance
during unmarshalling, it uses an implementor of ValueFactory
, which defines how to read an instance of the type from a portable
input stream (p 266-267). To allow this, the ORB must have a
value
factory registered for the valuetype's repository ID via
register_value_factory , which takes the ID and the
ValueFactory implementation. The operations
unregister_value_factory and lookup_value_factory
are also provided. In Java, these operations are provided by
org.omg.CORBA_2_3.ORB , a subclass of org.omg.CORBA.ORB,
but are currently unimplemented in the JDK's ORB (p 267).
4.4 The Portable Object Adapter (POA)
(Note: see sections 2.3.6, 5.14.4.2, 6.3,
and 10 in the text.)
4.4.1 Motivation and overview
The CORBA architecture is designed such that client use of an object
reference is intentionally simple: the client obtains the reference and
makes an invocation, as if the referenced object is always available.
The scalability options that define how to select and activate an
object that performs the operation are specified on the server using
the object adapter. For example, a business may have thousands of
customers, but it would be very expensive for all the corresponding
servants to remain active permanently. An object adaptor can be
configured such that it appears that all these objects are always
available, even though they are not all running at a particular time or
are implemented by a single servant (an application of information
hiding). On the other hand, we might have a CORBA object that
provides a calculator, e.g. for interest, amortization or present value
calculations. This object is a transient object whose lifespan is
that of the client reference (or even of a single invocation), which
has no state and need not be persisted. Intermediate between
these is an iterator over the customers that allows a client to process
them without obtaining thousands of references at once. Such an
object is a non-persistent object that has state.
Earlier versions of the CORBA specification (up through CORBA 2.2)
define one object adapter, the Basic Object Adapter (BOA), and imply
that others could be defined. The BOA was not completely
specified because it was not clear what scalability options would be
necessary nor how to express them. In particular, the BOA did not
have any capability for on-demand activation of servants. This
functionality was provided by most ORBs, but each ORB specified it in a
different manner. The OMG issued a Request For Proposals for a
vendor-independent object
adapter specification in 1995, and approved the ORB Portability Joint
Submission that defined the Portable Object Adapter in 1997.
The CORBA POA specification (chapter 11) states the following goals for
its POA design:
- Allow programmers to construct object implementations that are
portable between different ORB products
- Provide support for objects with persistent identities.
More precisely, the POA is designed to allow programmers to build
object implementations that can provide consistent service for objects
whose lifetimes (from the perspective of a client holding a reference
for such an object) span multiple server lifetimes
- Provide support for transparent activation of objects
- Allow a single servant to support multiple object identities
simultaneously
- Allow multiple distinct instances of the POA to exist in a server
- Provide support for transient objects with minimal programming
effort and overhead
- Provide support for implicit activation of servants with
POA-allocated Object IDs
- Allow object implementations to be maximally responsible for an
object’s behavior. Specifically, an implementation can control an
object’s behavior by establishing the datum that defines an object’s
identity, determining the relationship between the object’s identity
and the object’s state, managing the storage and retrieval of the
object’s state, providing the code that will be executed in response
to requests, and determining whether or not the object exists at any
point in time.
- Avoid requiring the ORB to maintain persistent state describing
individual objects, their identities, where their state is stored,
whether certain identity values have been previously used or not,
whether an object has ceased to exist or not, and so on
- Provide an extensible mechanism for associating policy
information with objects implemented in the POA
- Allow programmers to construct object implementations that
inherit from static skeleton classes generated by OMG IDL compilers
or from
a DSI implementation
The functionality of performing a request is provided
by the combination of a POA and a servant that implements the
operation. The primary responsibilities of a POA are to:
- create and manage object references
- map an object reference that a client uses as a request target to
a servant that performs the request when the ORB processes the request
This design decouples the identity of the CORBA object (the object
reference) from its implementation (a servant). The POA supports
a range of servant lifetime and activation "policies". We will
see that the relationship between object references and servants can be
dynamic and can be one-to-one, many-to-one, or one-to-many, depending
on the POA's policies. In addition, the lifetimes of object
references and servants are completely decoupled: an object reference
can be created without any active servant, a servant can be created
without associating it with an object reference, an existing servant
can incarnate a new reference, a new servant can incarnate an existing
reference, and a
servant or reference can be destroyed independently. The
association
is made when a request is processed according to the POA's polcies (of
course, a particular association can be set beforehand as well).
The root POA is a special default POA created by the ORB which
is accessed with orb.resolve_initial_references("RootPOA")
. A POA's policies are set when it is created
and cannot be modified subsequently, so all object references and
servants managed by a given POA are mapped using the same procedure.
CORBA supports creating multiple POAs so that a server program
can organize the application's servants and provide multiple policies
(and multiple servant managers and adapter activators) for those
servants.
POAs are created as children of existing POAs by calling
POA::create_POA , which takes the new POA's name, POA manager,
and policies (IDL p 74, Java p 239). This results in a tree of
POAs rooted at
the root POA. The names of sibling POAs must be unique.
However,
the ORB ensures that POAs created by one server program are distinct
from
those created by another, even if their names are the same. The
POA's
name and parent are accessed with the read-only attributes POA::the_name
and POA::the_parent , respectively (p 75). The
operation find_POA (p 74) returns the child POA with the
argument name, and may create the child POA if the parent POA has an
adapter activator (discussed in section 4.4.7 below).
Each POA has (figure p 69):
- child POAs (if any)
- a "POA manager" that determines its "processing state"
- if its Servant Retention Policy is
RETAIN, an
"Active Object Map" that maps object IDs to servants (possibly
many-to-one)
- if its Request Processing Policy is
USE_DEFAULT_SERVANT
, a "default servant"
USE_SERVANT_MANAGER
, a "servant manager"- an optional "adapter activator" to create child POAs
A POA manager encapsulates the processing state of each POA
associated with it, i.e. whether the POA is active
and whether it queues or discards requests rather than executing
them. The Active Object Map maps object IDs to servants,
and is used to look up the servant to invoke for a given request.
Entering a servant into the map is called activating the
servant, and the servant is said to incarnate the object. Deactivating
the servant removes it from the map, and we say that the object has
been etherealized . Note that clients are never aware
of activations and deactivations. A default servant is
used in situations in which a single implementation services the object
references managed by the POA that are not in its Active Object Map.
A servant manager is a callback interface invoked by a
POA with particular policy settings, whose implementation returns an
activated servant to execute the request. An adapter activator
allows a POA to create child POAs as necessary when receiving a
request. It provides an alternative to creating all the necessary
POAs when the server program starts.
The POA-related interfaces that we describe in this section are local
interfaces defined in the IDL module PortableServer ,
which is mapped to the Java package org.omg.PortableServer
. For example, the IDL local interface PortableServer::POA
is mapped to the interfaces org.omg.PortableServer.POAOperations
and org.omg.PortableServer.POA. Since the IDL
interface is local, a POA object reference cannot be exported to
another process or stringified.
4.4.2 Policies
Policies permit configuring many of the details
of a POA's behavior. (The designers of the POA chose to use
policy configuration for these options rather than defining a set of
POA types.) CORBA defines seven policies for POAs that specify
(p 71-72):
- whether CORBA objects are persistent (the Lifespan Policy)
- how object IDs are generated, and whether a servant can handle
requests from multiple object IDs (the ID Assignment Policy and the ID
Uniqueness Policy)
- how the POA locates a servant to execute a request (the Servant
Retention Policy, the Request Processing Policy, and the Implicit
Activation Policy)
- the concurrency model used to execute requests (the Thread Policy)
For each policy, there is an enumeration that defines a set of choices
for that policy, and some choices have an accompanying callback
interface that allows the programmer to code the necessary
behavior. The IDL for the PortableServer module
defines each specific policy as an enumeration listing the choices and
a local interface derived from CORBA::Policy with a
read-only attribute value (p 72: typo the header "interface
LifeSpanPolicy" should be "local
interface LifeSpanPolicy : CORBA::Policy "). A policy
object is created from an enumeration value by a POA with the methods
POA::create_lifespan_policy ,
POA::create_servant_retention_policy and so on (p 73). For
example, the parent POA can be used to create the policy objects
necessary to initialize a new child (p 239).
Policies are not inherited from the parent POA, but must be specified
when a POA is created. POA
operations that are not valid
for the target POA's policies (e.g., activate_object
with NON_RETAIN ) signal the exception
WrongPolicy .
The Lifespan Policy determines whether the CORBA objects
managed by the POA are available after the POA has been destroyed.
The default value TRANSIENT indicates that all
request to a POA made after its POA manager enters
the deactivated state (see below) signal the exception OBJECT_NOT_EXIST
. The value PERSISTENT indicates that
the objects implemented in the POA can outlive the process in which
they were created. If a transient POA is destroyed and then
restarted (including when the ORB or server process crashes), all
existing
object references that it had created are no longer valid, even if
upon starting a new POA is created with the same path name and it
creates
equivalent servants with the same object IDs as those references.
Note that when using the PERSISTENT policy, it is
the application's responsibility to store and retrieve the persistent
data that represents the state of the object: the policy choice only
indicates that, given an object reference, if a POA with the path in
that reference is created and that POA creates an object reference with
the same object ID as the given reference, that requests to the given
reference will be handled by the new reference and POA. Transient
objects are typically used for short-term "session" objects that
represent a user interaction or domain process, and persistent objects
are typically used for "entity" objects that represent objects in the
application's
domain. It is poor practice to store an object reference from a
transient POA in a persistent service such as the Naming or Trading
services
or to store a stringified IOR for that object.
The ID Uniqueness Policy specifies whether each servant
activated by the POA corresponds to a single object ID. The
default value UNIQUE_ID indicates
that a servant can handle requests from one CORBA object only, while
the value MULTIPLE_ID indicates that a servant can
handle requests from multiple CORBA objects, i.e. multiple object
IDs in the Active Servant Map can map to the same servant. With
the UNIQUE_ID policy, if an attempt is made to activate
a servant that is already in the Active Object Map, the exception
POA::ServantAlreadyActive is signaled.
The ID Assignment Policy indicates whether object IDs are
assigned by the POA (the default value SYSTEM_ID ) or by
the application (the value USER_ID). For example,
an application typically uses USER_ID with persistent
objects, and assigns the object's database ID as the object
ID so that it can use the ID to access the object's stored values.
On the other hand, for short-term service or session objects
such as a calculator, SYSTEM_ID relieves the programmer
of generating IDs.
The Servant Retention Policy determines whether the POA retains
active servants in its Active Object Map (the default value
RETAIN ) or not (the value NON_RETAIN ).
With RETAIN , the server program calls
POA::activate_object to enter servants in the Active Object Map
for use in later requests, and may
call POA::deactivate_object (which takes the object ID)
to remove servants from the Active Object Map. With
NON_RETAIN , no Active Object Map is present so the POA
controls the reference-servant mapping for each request using either
a default servant or a servant locator (a type of servant manager: see
below).
The Request Processing Policy specifies the
POA's behavior if it has the NON_RETAIN policy or
the target reference's object ID is not in the Active Servant Map.
The default value USE_ACTIVE_OBJECT_MAP_ONLY ,
which requires the RETAIN policy, indicates
that the exception OBJECT_NOT_EXIST should be
signaled if the object ID is not present in the map. In this
case, the server program must explicitly activate all the CORBA objects
that the
POA manages. With the value USE_SERVANT_MANAGER ,
the POA uses a servant manager to obtain a servant: if the POA has the
RETAIN policy, it calls ServantActivator::incarnate
, while if the POA has the NON_RETAIN policy, it calls ServantLocator::preinvoke
(discussed further below). With the value USE_DEFAULT_SERVANT
,
the POA accesses its default servant to perform the request. For
example, a default servant is a straightforward way to implement a
stateless
service. The NON_RETAIN policy requires
USE_SERVANT_MANAGER or USE_DEFAULT_SERVANT (since
the POA does not maintain servants), and USE_DEFAULT_SERVANT
requires MULTIPLE_ID (since the default servant
handles multiple object references).
The Implicit Activation Policy specifes whether the POA
supports implicit acitvation of servants (the value
IMPLICIT_ACTIVATION ) or not (the default value NO_IMPLICIT_ACTIVATION
), i.e. whether POA::servant_to_reference can be called
without activating the servant first. The value
IMPLICIT_ACTIVATION requires the SYSTEM_ID and
RETAIN policies.
The Thread Policy determines the concurrency
model used to execute requests for servants managed by that POA.
As always, a multithreaded model provides more throughput,
but requires the programmer to write multi-thread-aware code in
the servant implementations. The default value ORB_CTRL_MODEL
indicates that the POA is responsible for assigning requests
to threads. Most ORBs provide several configuration options
for the concurrency model, e.g. "single threaded", "thread per
client", "thread per request", and "thread pool" with specified pool
size limits. Most applications use a threading model provided
by the ORB vendor since most vendors implement several options and the
OMG has not fully addressed this issue. The value
SINGLE_THREAD_MODEL ensures that requests to the POA are
processed sequentially. The value MAIN_THREAD_MODEL
is similar, but allows
specifying that some code must run on a distinguished "main" thread
(MAIN_THREAD_MODEL is a recent addition).
The root POA's policies are the default policy values, except for the
Implicit Activation Policy:
- Lifespan Policy:
TRANSIENT
- ID Uniqueness Policy:
UNIQUE_ID
- ID Assignment Policy:
SYSTEM_ID
- Servant Retention Policy:
RETAIN
- Request Processing Policy:
USE_ACTIVE_OBJECT_MAP_ONLY
- Implicit Activation Policy:
IMPLICIT_ACTIVATION
- Thread Policy:
ORB_CTRL_MODEL
This combination of policies handles the simplest servant activation
process, namely non-persistent, implicitly pre-activated servants with
POA-assigned IDs. If this is appropriate for all the
application's CORBA objects, no other POAs need be created.
The choice of Servant Retention Policy and Request Processing Policy
for a given kind of object affects both response time and
resource usage. If the application activates all sevants
initially
(i.e., the POA uses the default RETAIN and USE_ACTIVE_OBJECT_MAP_ONLY
policy values), response time is reduced because the POA only needs to
look
up the servant in its Active Object Map upon receiving an invocation.
However, allocating all the application's objects uses the
maximum resources, so this strategy is most applicable when the objects
are relatively few and are accessed very frequently. The resource
usage can be reduced by using the RETAIN and
USE_SERVANT_MANAGER policies: the servant manager creates
servants as needed and enters them in the Active Object Map, and the
map contains only the objects that some client has accessed. The
application can also improve resource usage with the servant manager
strategy by deactivating objects that it determines are not likely
to be accessed by clients (although deciding when to deactivate is
often not straightforward to implement). This strategy is useful
when the application uses a very large number of objects, which results
in the memory
requirement for the servants and Active Object Map being
large. Using a servant manager rather than pre-activation is also
called for if the
number of objects cannot be determined in advance. Clearly, a POA
with the RETAIN and USE_SERVANT_MANAGER
policies is applicable for persistent objects that are numerous, e.g.
customers or inventory items. An application can use the
MULTIPLE_ID and USE_DEFAULT_SERVANT policies for a
single servant that performs a stateless service or responds to
requests for objects loaded from a database (discussed further below),
in which case that servant always exists. However, using a
default servant can be a bottleneck if the servant is stateful (as in
the second usage) because the servant can only process one request at a
time. If the servant requires significant resources, the POA
could instead use the USE_SERVANT_MANAGER and
NON_RETAIN policies. With these policies, a servant
locator would be used to
create a new servant for each request and to destroy it when the
request has been processed. In this case, the servant is
allocated only while a request is being processed. However, if
creating the servant takes significant processing or resources, this
approach negatively affects response time.
The IDL interface CORBA::Policy, which declares the
operations copy, destroy , and
policy_type , is mapped to the Java interfaces
org.omg.CORBA.Policy and PolicyOperations .
The policy type is one of a set of integers defined in
the PortableServer module ( THREAD_POLICY , LIFESPAN_POLICY
, etc.). The classes generated from the policy enumerations and
the operations and signature interfaces generated from the policy
interfaces are in the package org.omg.PortableServer.
Policies are not inherited from the parent POA, but
are specified when a POA is created. To give the policies
for a new POA, pass an array of Policy instances
that contains the policy values that differ from the defaults to
POA.create_POA . The policy objects in the array are
created
with the methods POA.create_lifespan_policy and so on,
which take the constant for the specifed value (p 239, 440-441).
The POA copies the policy objects so the caller can destroy those
objects after creating the POA (p 441).
4.4.3 Object references
The server program is responsible for creating object references so
that it can ensure that an object adaptor associates an implementation
with
the reference. An object reference may be passed from client to
client, but all that a client can do with the reference is make
requests. An object reference specifies:
- the interface type of the reference
- the host and port that created the reference
- the full path name of the POA that created the reference
- the object ID, a sequence of octets which uniquely
identifies that CORBA object
- optional information for services, e.g. security and transaction
information
In practice, the encoding of the object reference may contain routing
information to find the host or a compact descriptor that that ORB can
use to find the object ID. The object ID is a sequence of
octets that is created by the server program or generated by the POA,
depending on the POA's ID Assignment policy. Note that the
reference specifies the POA that created it, not the servant that
incarnates it.
An object reference is created by a POA using one of the following
operations:
POA::activate_object and POA::activate_object_with_id
enter the argument servant in the Active Object Map, and the
first returns the ORB-generated object ID. These operations
require
the RETAIN policy. The
exception ServantAlreadyActive is signaled
if the servant is already mapped and the POA has the UNIQUE_ID
policy. The object reference is then obtained with
POA::servant_to_reference or POA::id_to_reference
.POA::create_reference and POA::create_reference_with_id
create a reference of the type given by the argument
RepositoryId but do not associate it with a servant. The
first operation requires the SYSTEM_ID policy and the
second takes an object ID (p 235). The reference may then be
exported, and a servant will be selected when a client invokes a
request, e.g. the default servant or a servant
returned by the servant manager.POA::servant_to_reference can be called without
activating the servant first if the POA has the RETAIN
and IMPLICIT_ACTIVATION policies (p 236, 237). It
enters the argument servant in the Active Object Map with a
POA-generated ID and creates and returns an object reference.- The Java language mapping adds a method
_this(orb)
to each skeleton class which returns a reference to the CORBA
object that the servant incarnates (like servant_to_reference
). If the POA returned by the servant's _default_POA
method (the root POA if it has not been overridden) uses the
IMPLICIT_ACTIVATION policy, _this
can be used to activate the servant in that POA and create a reference
(p 441). However, this technique has the drawback that the POA
used is not apparent.
As stated above, POA operations that are not valid for the target POA's
policies signal the exception WrongPolicy . The POA
interface also defines operations to query to the mappings among
references, object IDs and servants, namely reference_to_id
, reference_to_servant , id_to_servant , servant_to_id
, and servant_to_reference , all of which can raise WrongPolicy
as well as WrongAdapter , ObjectNotActive
, or ServantNotActive (p 78).
Once an object reference is created, it can be exported to clients via
the Naming Service or a stringified IOR, or returned to a client as a
return value or an out parameter. To clients, it
will always
appear to refer to the same object. When a client issues a
request, its ORB uses information in the target object reference to
locate the host on which the object implementation exists or will be
activated. The transmitted request includes the POA name and
object ID of the target object from that reference. If the POA
does not exist, the adapter activator for each POA in the path to the
designated POA is used to create a POA. If this cannot be done,
the exception OBJECT_NOT_EXIST is signaled.
Finally, the POA's Servant Retention and Request Processing
Policies determine the servant whose method is invoked. If no
default servant or servant manager is available in a case that requires
one, the POA signals the OBJ_ADAPTER system exception.
4.4.4 Default servants
A default servant handles
requests for references not in the POA's
Active Object Map, and normally requires the MULTIPLE_ID
policy since the servant handles requests for multiple object
references. With the NON_RETAIN policy, the default
servant handles all requests to the POA's references. (Actually,
the only reason to use RETAIN with a default servant is
if the application pre-activates some specialized servants in the
Active Object Map. Otherwise, every entry in the map refers to
the default servant.) A default servant is defined like any
servant, i.e. either it extends an XXXPOA skeleton class
or an XXXPOATie instance delegates
to it and it must implement the interface's operations.
A default servant is registered with its POA by
POA::set_servant (p 453), and can be accessed by
POA::get_servant. Typically, a POA that uses a default
servant creates references to
export without activating them.
Common uses of default servants include:
- implementing a stateless service, e.g. a calculator or
time-of-day service
- responding to requests for instances of a particular class by
loading the corresponding object from a database, performing the
operation, and then storing the object (p 447-449)
- implementing a wrapper for system utilities, external hardware,
or a non-object-oriented legacy system
- implementing a single DSI servant for several CORBA object types
The second usage seems inefficient with respect to time because the
database is accessed for each request. We might consider having
the default servant maintain a cache of the accessed objects' state
information indexed by ID. However, this is not much different
from using a servant manager and caching servants that maintain the
state information in the Active Object Map, so it is rarely done.
In implementing the second usage, the default servant needs the
object ID of the current request target, but it cannot call servant_to_id
because it implements numerous CORBA objects. To obtain the
object ID, it must use the interface Current described
below.
In the Java language mapping, the class PortableServer.Servant
(the ancestor of all skeleton classes), provides a method _object_id
, which calls PortableServer.Current.get_object_id (p
440). As stated above, the single default server can be a
bottleneck in the last three usages.
4.4.5 Servant managers
A servant manager provides a
POA with the ability to select or create a servant on demand, i.e. when
a request is processed
on a reference for which no servant is activated. The servant
manager interfaces essentially define callback operations used by the
POA to obtain a servant and to notify the manager that a servant is not
longer in use. If the application pre-activates all the necessary
servants or uses a default servant, it does not need a servant manager.
The local interface PortableServer::ServantManager
defines no operations, but serves as the base interface for the local
interfaces ServantActivator and ServantLocator
, which define the operations for the two types of servant managers.
A servant activator is
used with the RETAIN
Servant Retention Policy and a servant
locator is used with the NON_RETAIN
policy. Since servant managers are objects, they must be
activated (p 441: activation using _this ). The
object reference that refers to the servant is then passed to POA::set_servant_manager
to register the servant manager (p 441). A POA's servant manager
can be accessed with POA::get_servant_manager .
The ServantActivator interface defines two operations:
local interface ServantActivator : ServantManager {
Servant incarnate(in ObjectId oid, in POA adapter) raises (ForwardRequest);
void etherialize(in ObjectId oid, in POA adapter, in Servant serv,
in boolean cleanup_in_progress, in boolean remaining_activations);
};
If the object ID for the target of a request is not in the
Active Object Map, the POA calls ServantActivator::incarnate
to obtain a servant. It then enters the servant in the Active
Object Map (so subsequent requests for that object ID do not invoke the
servant activator), and invokes the servant's method. If the
servant
activator signals ForwardRequest, the ORB must deliver
the current request and subsequent requests for the given object
reference
to the object reference in the forward_reference field
in the exception (i.e., this is how the POA handles the exception).
This
feature is provided to support mobile object implementations and load
balancing. When a servant is deactivated, the POA calls ServantActivator::etherialize
, which gives the servant manager an opportunity to release resources
used by the servant (and delete it in C++). Note that if the POA
has a servant activator, it calls etherialize for every
servant deactivation, not just those servants that were created by the
servant activator. etherialize is also called
for each active object if destroy is called on the POA
or the POA's manager is made inactive with
POAManager::deactivate . Some ORBs also have configuration
properties such as a limit on the number of active objects or a timeout
period for active objects
that can cause deactivation, resulting in a call to etherialize
. The argument cleanup_in_progress is true if
the parameter etherialize_objects was true in the
call to destroy or deactivate .
The argument remaining_activations is true if the
servant
being deactivated is associated with other object IDs besides oid
in the Active Object Map. The POA removes the servant from
the Active Object Map and ensures that all pending requests are
processed
before calling etherialize. The CORBA specification
states that the POA is responsible for serializing calls to incarnate
and calls to etherialize.
Using a servant activator is a case of "lazy instantiation". When
a client obtains an object reference, e.g. via a factory opeation, that
method creates an object
reference with create_reference or create_reference_with_id
and returns it, but does not create a servant. Instead, all
servants are created in the servant activator's incarnate
method when the client makes the first request to the object. If
the servant activator is used with persistent objects (the typical
case), the factory method that creates an object creates the database
records that store the initial values of the object, as well as
creating and returning an object reference. The factory method
that finds an existing object simply creates and returns the object
reference.
As stated above, using a servant manager allows the application to
control servants resource usage: to do so, the application selects
servants for deactivation, i.e. it implements an "eviction" strategy.
This
process can be triggered by the client when it is finished processing
an object, e.g. by a destroy operation in the object's
interface, or by the server. Two simple eviction strategies are
enforcing a
limit on the number of active servants and enforcing a time limit on
the
lifetime of a servant. Deactivating servants when the time
between
requests is above a limit is somewhat more complicated. Of
course,
an application can also use an eviction strategy based on knowledge of
typical use of the application or of its domain. POA::deactivate_object
takes the object ID and can signal
ObjectNotActive or WrongPolicy (due to the
NON_RETAIN policy). The object ID is removed from the
Active Object Map immediately and the method returns. If there
are requests pending for that object, they are processed before etherialize
is called.
Servant activator implementations extend the class org.omg.PortableServer.ServantActivatorPOA
. For example, suppose that we implement eviction with a size
limit for the Active Object Map and the simple strategy of evicting the
oldest servant:
import org.omg.PortableServer.*;
public class XXXActivatorImpl extends ServantActivatorPOA {
private int maxAOMSize;
// a FIFO queue of activated object IDs
private LinkedList idQueue = new LinkedList();
public XXXActivatorImpl(int maxAOMSize) {
this.maxAOMSize = maxAOMSize;
}
public Servant incarnate(byte[] oid, POA poa) throws ForwardRequest {
if (idQueue.size() == maxAOMSize) {
byte[] deactivateID = (byte[]) idQueue.removeFirst();
try {
poa.deactivate_object(deactivateID);
}
catch (org.omg.PortableServer.POAPackage.ObjectNotActive objNotActive) {
// should not happen: the object is activated
}
catch (org.omg.PortableServer.POAPackage.WrongPolicy wrongPolicy) {
// should not happen: we set the POA policies
}
}
idQueue.addLast(oid);
// e.g., use the oid to get initial field values from the database
return new XXXImpl(oid, poa);
}
public void etherealize(byte[] oid, POA poa, Servant servant,
boolean cleanup_in_progress, boolean remaining_activations) {
// ID deleted from queue by incarnate
}
}
If this were a C++ program, etherealize would
delete the servant when remaining_activations is false.
The interface ServantLocator used for a servant manager
with the
NON_RETAIN policy defines two operations:
local interface ServantLocator : ServantManager {
Servant preinvoke(in ObjectId oid, in POA adapter, in CORBA::Identifier operation,
out Cookie the_cookie) raises (ForwardRequest);
void postinvoke(in ObjectId oid, in POA adapter, in CORBA::Identifier operation,
in Cookie the_cookie, in Servant the_servant);
};
The POA calls preinvoke to obtain a servant and
then calls postinvoke immediately after the servant
executes the request. The postinvoke call is
considered part of processing the request: if it raises a system
exception, the request execution signals that exception to the client
rather than
returning. Since the servant returned by the locator is usually
used for one request only (i.e., the locator creates a new servant for
each invocation), the POA passes the operation name to the locator so
that it can optimize the servant for that operation if desired.
The the_cookie parameter allows the servant locator
to set some information in preinvoke that will be
delivered to postinvoke by the POA. The portable
server IDL declares the type Cookie as a native
type, which is mapped to java.lang.Object and org.omg.PortableServer.CookieHolder
in Java. The ForwardRequest exception is used in
the same manner as for ServantActivator::incarnate.
When using a servant locator for a set of persistent objects, the
locator uses the object ID to load the object's state from storage when
creating the servant implementation (p 437-438) and then stores the
object if necessary in postinvoke (p 439).
4.4.6 The POA manager
A POA manager controls the flow of requests into each POA
associated with it by providing methods to change the processing
state of those POAs. It is defined
by the local interface PortableServer::POAManager .
A POA is associated with a POA manager by passing the manager to
POA::create_POA . If that argument is null, a new POA
manager for the POA is created. A POA's manager is
accessible as the read-only attribute POA::the_POAManager
. For example, if an application wishes to change the processing
state of a group of POAs as a unit, it can create the first POA, access
its POA manager, and then pass that manager to POA::create_POA
when creating the other POAs. The root
POA's manager is created
by the ORB together with the root POA. The processing states are
defined by the enumeration PortableServer::POAManager::State
, which has the values ACTIVE , HOLDING ,
DISCARDING and INACTIVE , and a
manager's state is accessed with POAManager::get_state .
POAManager::get_id returns the manager's
string ID, which is "RootPOAManager" for the root POA's
manager.
Initially, a POA manager is in the holding state, in which the
associated POAs will queue incoming requests and will not call adapter
activators (those operations are also queued). The number of
requests that can be queued is determined by the ORB
implementation: when it is exceeded, requests are discarded and the TRANSIENT
system exception is signaled. (Generally,
the exception TRANSIENT means that the client
should try the request again.) The POA manager can be
placed in the holding state with POAManager::hold_requests
, whose boolean argument indicates whether to wait until all
current requests are processed before returning.
When the POA manager is in the active state,
the associated POAs receive and process requests. (Request
queueing may
still occur due to availability of system resources such as threads.)
The POA manager is placed in the active state with POAManager::activate
. Clearly, the POA manager should not be activated until all the
associated POAs are created and ready to process requests.
When the POA manager is in the discarding state, the associated
POAs discard requests and signal the TRANSIENT exception.
In addition, adapter activators are not called to create child
POAs in this state. The discarding state is primarily provided so
that the server application can deal with situations in
which a servant or group of servants is receiving too many requests
for the resources available. The POA manager is placed in the
discarding state with POAManager::discard_requests
The POA manager is placed in the inactive state when the
associated POAs are to be destroyed with POAManager::deactivate.
In this case, the associated POAs will no longer process requests (the
CORBA
specification leaves the exception signaled to the ORB
implementor).
POAManager::deactivate takes two boolean arguments:
the first indicates whether the associated POAs which have the RETAIN
and USE_SERVANT_MANAGER policies should call
ServantActivor::etherialize for each active object, and the
second indicates whether to wait until all current requests are
processed before returning. Once a POA manager is inactive,
attempts to change its state signal the exception
AdapterInactive .
4.4.7 Adapter activators
As stated above, an adapter activator allows a POA
to create child POAs as necessary. POAs are typically created
with POA::createPOA . The operation POA::find_POA
takes a child POA name and a boolean activate_it (p 74),
and returns the child with the given name. If there is no such
child POA and activate_it is false, the exception
AdapterNonExistent is raised. However if there is no such
child and activate_it is true, the POA's adapter
activator is called to create the child. The adapter
activator is also used when processing a request if there are POAs in
the path name that are not yet created (i.e., the process of following
the POA path name calls find_POA(name, TRUE) ).
The adapter activator is set or accessed via the attribute POA::the_activator.
The AdapterActivator interface has a single
operation, unknown_adapter that takes the parent POA and
the child POA name, and returns whether it successfully created
the given child (p 75). The application's implementation class
creates a child of
the given parent with the given name and the desired policies, and may
also set a servant manager, default servant, or adapter activator for
the new POA. If the method cannot create the child, it returns
false, in which case the POA signals OBJECT_NOT_EXIST.
POAs are not persistent and must be recreated when the server program
executes. If an ORB stops and restarts, the POAs that existed are
not recreated automatically, so the ORB cannot forward requests on
existing persistent object references to the servants. To handle
this situation, the server program can define an adapter activator for
each parent POA to create a child POA when a request occurs that
targets
an object reference managed by that child. (Alternatively,
developers can write a ORB startup script that executes the necessary
server programs.) The adapter activator can also be used for lazy
instantiation of POAs to reduce resource usage.
4.4.8 The interface Current
When a servant implements operations for multiple object IDs, it may
need to know the object for which it is processing a request or its
POA. The
IDL local interface PortableServer::Current defines the
operations get_object_id and get_POA for
this purpose (p 79). It extends the interface CORBA::Current
, which defines no operations. The program accesses an
implementation of Current with ORB::resolve_initial_references("POACurrent"),
and that object may only be used within a POA-dispatched operation
(otherwise, its methods signal the exception NoContext).
In the Java language mapping, the class org.omg.PortableServer.Servant,
which is the ancestor of all skeleton classes, defines the convenience
methods _object_id and _poa that obtain an
implementation of Current and invoke get_object_id
or get_POA, respectively. These methods have the
same restriction, i.e. they must be invoked within a POA-dispatched
operation. That class also defines the conveinence method _orb
for accessing the ORB.
4.5 DSI/DII
***BV&D 2.3.11 Interface Repository and type info
***BV&D 2.3.9, 6.4-5 TypeCode, Any and DynamicAny
***BV&D 2.3.10, 6.6-7, 9.2-4 dynamic invocation and dynamic
skeleton interfaces
4.6 Interceptors
***BV&D 9.5
5. CORBA Services
5.1 The Naming Service
5.1.1 Overview
The CORBA Naming Service is essentially a remotely-accessible database
of object references
by name. It used by clients to obtain object references,
called resolving the name, and by servers to make object
references available, called binding the object reference to a
name. Typically, the server program binds an object reference
upon creation
and unbinds it upon destruction. Unlike the RMI naming service,
names can be organized into naming contexts, similar to the
organization of files into directories. In fact, the CORBA
specification does not prohibit a context from being bound in more than
one context, so
the context structure can be a directed graph and can even include
cycles. A naming service can provide persistent access across
server executions: upon starting, the server binds the new object
reference to the existing name.
If a client has cached the previous reference, it will still be
effective if the POA used the persistent lifespan policy and the
server, port, and object ID are the same. If not, client
operations on the old reference will
fail, but the client can refresh the reference by accessing it in the
same way from the naming service and continue.
The original CORBA Naming Service specfied IDL for binding and
resolving names and listing the names available. The CORBA
Interoperable Naming Service adds support for standard external string
formats for names
and conversions between these strings and names, and specifies the
semantics of some operations more precisely.
The IDL for the CORBA Naming Service is specified in the module
CosNaming, which is mapped to the Java package
org.omg.CosNaming. (COS stands for Common Object
Services.)
5.1.2 The interface NamingContext and related types
The structure NameComponent (p 271) has two fields:
id is the string used to identify the component, and kind
is a string for application-specific use, often used to indicate how
the object is used, similar to a file extension. (The type alias
Istring was intended for internationalization.) The field
values may contain spaces or be empty strings. The kind
field is not used by the naming service, except that names with the
same id but different kind fields are considered distinct. The
CosNaming IDL defines the type Name as
sequence<NameComponent>, which is mapped to
NameComponent[] in Java. Such a "compound name" can
be thought of as a naming context path in which each component names
a context, except the last, which can name a context or an object.
For example:
NameComponent[] name = new NameComponent[]{
new NameComponent("uic", "school"), new NameComponent("cs", "dept"), NameComponent("ai", lab")};
We will see a more convenient way to use naming context path names in
the
next section.
The interface NamingContext defines the basic operations
for binding and resolving names, creating contexts, and determining
the context structure (p 273-277). There are two types of
bindings, object bindings and context bindings. An object binding
is not used in name resolution, i.e. resolution never looks for its
child contexts. The operation bind creates an
object
binding, and rebind replaces an object binding (it raises
the exception NotFound if the name was not previously
bound to
a context). The operations bind_context and
rebind_context create or replace context bindings
(creating a naming context to use as the argument is discussed below).
For all four operations, the given name is interpreted relative to the
target naming context, and all the naming contexts corresponding to the
components in the given name except
for the last must already be bound (i.e., only one name component can
be bound per call). That is, the target of a binding operation
can be any ancestor of the new object or context, although programmers
usually use the parent context. These four operations are used by
a server
to create a context structure and bind objects within it. The
operations can signal the expected exceptions (p 275). The
operation
unbind removes a context or object binding (p 274).
The operation resolve returns the object or context bound
to the given name relative to the target context (p 274). At each
name
component, it looks for an object binding first, otherwise it narrows
the object to NamingContext and recurses on the
remainder of the name. resolve returns CORBA::Object
, so the caller must narrow the result to the expected type. If
the result of the narrowing is null, either no object was bound or the
wrong type of object was bound.
The operation NamingContext::new_context creates
a new unbound context implemented by the same naming server which can
then be bound in any context (p 276). The operation bind_new_context
creates a new context and binds it in the target context.
Typically, a program that adds to a naming context hierarchy simply
calls bind_new_context on the parent context, passing the
child name. The
operation destroy releases the resources used by the
target context and deletes it, and signals the exception
NotEmpty if that context contains bindings. Note that a
context must be unbound before destroying it.
The CosNaming IDL represents a binding with
the enumeration BindingType and the structure Binding
(p 272). (A comment in the IDL notes that the binding_name
field should be of type NameComponent, not Name,
but was not changed for backward compatiblity. The binding_name
value will always be a Name of length one.) The
operation NamingContext::list provides access to the
bindings in the target context (p 276-277). To handle the
possiblility of a very large number of bindings, the parameter how_many
specifies the number of bindings to be returned in each call. The
output parameters are a sequence<Binding> of the
specified size (or fewer) and a BindingIterator, which
provides access to the remainder of the bindings. If all the
bindings are returned in the sequence, the binding iterator is null.
The interface BindingIterator defines the
operations next_one and next_n to access
further bindings, both of which return whether there are more bindings
(p 277). In fact, the CORBA specification does not state that the
list operation must return as many bindings as requested if they exist,
i.e. how_many is the maximum to return.
The caller must check whether the iterator is null to determine
whether all the bindings have been returned. The same is true of
BindingIterator::next_n: the caller must check the return
value.
Like any other CORBA object, a naming context is represented by an
object reference. A program obtains a reference to the initial
context of the Naming Service registered with the ORB via
orb.resolve_initial_references("NameService") (p 281).
The CORBA Naming Service Specification states that this object will be
an implementation of NamingContextExt, which is discussed
in the next section. Like any CORBA object,
a naming context can be exported to other ORBs, which supports linking
distinct naming servers to provide a "federated naming service".
In
this case, resolving a name (i.e., a list of name components) can cross
from one process or host to another.
5.1.3 The interface NamingContextExt
The CORBA Interoperable Naming Service introduces the interface
NamingContextExt , which extends NamingContext and
defines operations for converting between names and external string
formats (p 278). (A new interface was introduced rather than
adding operations to NamingContext for backward
compatibility.) The simplest format, a stringified name,
represents each name component as id.kind and
separates the components in a name with forward slashes, e.g.
"uic.school/cs.dept/ai.lab"
(note that this is not the same as a stringified IOR). Periods
and slashes can be used within the name
and kind fields by escaping them with a backslash
(although this is considered poor practice). The operation
NamingContextExt::to_string converts a name to a string
in this format, and NamingContextExt::to_name converts
a stringified name to a name. NamingContextExt::resolve_str
takes a string in this format and returns the object reference
bound to that name, relative to the target context (i.e., like
to_name followed by resolve).
Stringified names are easier to read, construct, store, and retrieve
than a sequence of name component objects and are language-independent,
but do not include host information or a target context.
Furthermore, a stringified name is relative to a context so its use
requires a reference to some parent context, i.e. the target of
to_name. CORBA defines four URL formats for
specifying
the location of a CORBA object exported by a naming service, any of
which can be passed to ORB::string_to_object to obtain
the given object (or context). (In fact, the stringified IOR
format IOR:<hex_octets> is a valid URL, but it is
opaque and very long.) As in all URLs, non-ASCII characters and
the space character must be "escaped" by representing them as
% followed by two hexadecimal digits giving the character
value (e.g., the string "cool service" is written as
cool%20service). The formats are:
corbaloc:rir:[/ObjectId] specifies an object
that is found by calling orb.resolve_initial_references,
passing ObjectId. If ObjectId
is omitted, "NameService" is used.corbaname:rir:[/NameService][#stringified_name]
specifies an object that is found by resolving the stringified name
relative to the initial context (i.e., with resolve_str
). The "/NameService" is optional.corbaloc:[iiop]:[version@]host[:port
][/ object_key] specifies the location of a CORBA object
in a relatively readable form. The iiop,
version @ , :port, and /
object_key are optional: the default IIOP version
is 1.0, the default port is 2089, and the default object key is NameService
. The object_key is the ORB-specific
portion of an IOR that specifies the object ID and POA (an octet
sequence escaped as necessary), but is usually a string that can be
used as an argument to resolve_initial_references
(e.g., TradingService). corbaname:[iiop]:[version@]host[:port
][/ object_key][#stringified_name]
specifies a naming context via object_key, in
which stringified_name is resolved to
obtain an object reference. If no object_key
is given, the key NameService is used.
The corbaname formats are essentially a corbaloc
URL followed by a # and a stringified name, and can only
be used if the corbaloc portion identifies a naming
context. corbaloc URLs are independent of
naming services and can be used to refer to any CORBA object.
Note that the rir versions do not
give host information, so they access the naming service on the host
that interprets them. Generally, strings used with
resolve_initial_references will be the only object keys
used with the iiop formats since ORB-specific keys are
not visible outside the ORB. Note also that the ORB can find
those objects without knowing the POA and object ID. To provide
a URL for an application-specific object, bind it
in a naming service and publish a corbaname URL.
Both
iiop URLs allow giving a comma-separated list of
[version @]host[: port] addresses to provide
fault tolerance. When interpreting the URL, the ORB tries the
first address and if it fails, tries the second, and so on.
The following are some examples (see also p 280):
corbaloc:rir:/InterfaceRepository
corbaname:rir:#uic.school/cs.dept/ai.lab/travel%20times.service
corbaloc:iiop:1.2@foo.bar.org,1.1@foo2.bar.org:2345/the%20key
corbaname::1.2@ai.cs.uic.edu#transportation%services.ctx/travel%20times.service
The operation NamingContextExt::to_url
takes a corbaloc URL and a stringified name, and performs
any escaping necessary and returns a string giving the URL (p 278).
The example class ContextLister (p 281-3) recursively
lists the bindings in a context and the contexts bound in it (p 284).
The context is the ORB's initial context or can be set by passing
a stringified IOR. Contexts are marked to avoid infinite
recursion since the context graph may have shared subtrees and cycles.
to_string is used to print each context or object.
5.1.4 Specifying initial references
Although a naming service is essential to writing robust CORBA
applications, it is not part of the ORB: it is a separate process that
must be started individually before starting the ORB processes that use
it. Due to its importance, all ORB vendors provide an
implementation
of the Naming Service. The Java Develpoment Kit includes the
program orbd, which implements a persistent Naming
Service.
The command line option -ORBInitRef with a stringified
IOR or CORBA URL value can be passed to the ORB to specify the objects
obtained by orb.resolve_initial_reference. The
option -ORBDefaultInitRef with a CORBA URL can be passed
to the ORB to give a naming service from which all initial references
are obtained. For example:
server -ORBInitRef NameService=IOR:010483c2af45d............
server -ORBInitRef NameService=corbaloc::foo.bar.org:5555
server -ORBDefaultInitRef corbaloc::1.2@foo.bar.org/init%20refs
For example, an organization could use this capability to
provide a single naming service for multiple server hosts. The
host and port for the naming service can be set in the Java ORB by
passing a properties file to ORB.init as follows:
Properties props = new Properties();
props.put("org.omg.CORBA.ORBInitialPort", "5555");
props.put("org.omg.CORBA.ORBInitialHost", "foo.bar.org");
ORB orb = ORB.init(args, props);
5.2 The Event and Notification Services
5.2.1 Event notification concepts
An event is an atomic occurrence, typically a operation
invocation or a change of state of some object, of which other object
wish to be informed. An event notification is a mechanism
for informing those objects, and includes information about the event
and often about results of the event occurrence. In CORBA, the
source of the event is called the supplier and the objects
notified are called consumers.
The concept of event notification in CORBA is like that of a
distributed messaging service rather than that of AWT/Swing event
notification. In particular, event-driven communication differs
from invocation-based communication in that:
- the supplier has no knowledge of the consumers and vice versa
- notification is many-to-many: a supplier's notification can be
passed to mulitple consumers and a consumer can receive notification
from multiple suppliers (rather than the one-to-one relationship of an
invocation)
- notification is non-blocking for the supplier
- notification can involve implicit reception (i.e., the consumer
takes to action to receive the event)
This concept of event notification differs significantly from AWT/Swing
event notification, an example of the Observer pattern, which is
invocation-based. With the Java UI framework, the component, like
any observable, has an explicit list of its listeners and the listener
usually has a component reference which it uses to update its state.
For example, an ItemEvent does not give the
selected item: the listener must query the combo box or list.
Furthermore, Java UI notification involves a direct synchronous
method call to each listener. Also, Java UI notification differs
from the CORBA Event Service in that it is local to the virtual
machine. Since a consumer can receive notifications from multiple
suppliers, the event notification must be self-describing and the
consumer must parse the notification data to determine how to respond.
Since the supplier has no knowledge of the consumers, there
should be no consumer-influenced data in the notification.
To achieve these properties, the supplier and consumers are decoupled
and communicate via an intermediary (the Mediator pattern), called an
event channel in the CORBA Event Service. The event channel
is the supplier for the consumers and is the consumer for suppliers,
and the suppliers and consumers interact with the channel only.
This characteristic allows easier reconfiguration of the system,
e.g. adding or removing consumers does not affect the supplier.
It also means that a supplier can notify the channel without
blocking while all consumers are notified. Because the supplier
and consumers should be loosely coupled, IDL has no mechanism for
indicating that a particular operation will issue notifications.
This allows notifications to be added and removed to methods
without affecting their interfaces.
Like messaging services, CORBA supports two notification models:
- With the push model, notification is initiated by the
supplier: it notifies the channel, which invokes a callback operation
in each consumer (p 474)
- With the pull model, notification is initiated by the
consumer: it notifies the channel that it wishes to receive any
notifications available, and the channel invokes a callback operation
in each supplier (p 475). The consumer opreation can either wait
for a notification if none is available (
pull in CORBA) or
return immediately whether a notification has occurred or not (try_pull
in CORBA).
The terms "push" and "pull" describe the model with respect to the
supplier. The channel acts as a proxy consumer for the
supplier and a proxy supplier for the consumer (the Proxy
pattern). Because of the channel's role as a mediator, it is
possible to use mixed-mode notification (p 475), e.g. the supplier can
push notifications to the channel which caches then unitl consumers
pull them.
5.2.2 The Event Service
To keep the notification data generic, it is wrapped in an any
, which is mapped to the class org.omg.CORBA.Any in Java.
In Java, the supplier obtains an instance with orb.create_any
and then uses XXXHelper.insert to set object data in the
Any , which also sets its type code (p 491):
Any eventData = orb.create_any();
XXXHelper.insert(eventData, xxx);
To check the type of an object wrapped in an Any,
the consumer accesses the TypeCode with any.type
and then compares the type code's ID with that of an expected object's
class. It then extracts the object with XXXHelper.extract
(p 496):
if (eventData.type().id().equals(XXXHelper.id()) {
xxx = XXXHelper.extract(eventData);
// ... process xxx ...
}
The class org.omg.CORBA.Any defines operations
to insert and extract primitive type values (e.g., insert_string
and extract_fixed). Type codes for primitive types
do not have IDs, so the consumer must create a TypeCode
with a method in org.omg.CORBA.ORB (e.g., create_string_tc
) and compare it with that in the Any with TypeCode.equal
. The use of any in the Event Service IDL is
considered a drawback because insertion and extraction are generally
expensive operations.
The basic interfaces for push and pull consumers and suppliers are
defined in the IDL module CosEventComm (p 476-8).
The interfaces PushConsumer and PushSupplier
support the push model in which the supplier has a reference to a
consumer and calls push to perform notification.
The interfaces PullSupplier and PullConsumer
support the pull model in which the consumer has a reference to a
supplier and calls pull or try_pull to
receive notification. The operation pull blocks
until a notification is available if there is none (or until an
exception is raised). try_pull never blocks: it
returns whether a notification exists or not, and the output parameter has_event
indicates whether there was a notification. These four interfaces
also define methods to disconnect from the notification and the module
defines the exception Disconnected (p 476), but they do
not include connect operations, which we discuss next.
The interfaces for using event channels and connecting consumers and
suppliers are defined in the IDL module CosEventChannelAdmin
. The proxy interfaces are used by suppliers and consumers to
connect with the channel and perform notification, and are implemented
by objects within a vendor's Event Service implementation. The
module also defines administration interfaces for obtaining the objects
within the channel implementation
that perform these roles. The proxy interfaces each extend the
corresponding interface in CosEventComm with the
appripriate connect operation (p 479-480):
ProxyPushConsumer extends PushConsumer
with connect_push_supplierProxyPushSupplier extends PushSupplier
with connect_push_consumerProxyPullConsumer extends PullConsumer
with connect_pull_supplier ProxyPullSupplier extends PullSupplier
with connect_pull_consumer
All the above connect operations can signal the exception AlreadyConnected
. (The exception TypeError is used with the typed
interfaces discussed below.) The channel invokes the disconnect
operation on the object passed to connect when it wishes to disconnect
from that supplier or consumer. The SupplierAdmin
and ConsumerAdmin provide access to implementations of
the proxy interfaces within the channel, and implementations of those
interfaces are obtained via methods in the interface EventChannel
(p 481).
The Event Service IDL does not define any mechanism for obtaining event
channels, e.g. an event channel factory. Typically, an event
channel is obtained via orb.resolve_initial_references("EventService")
or a naming service. ORB vendors provide various mechanisms for
registering an event service with the ORB (command line options,
properties files, administration tools, etc.).
To establish a connection and deliver or obtain notifications, the
supplier or consumer obtains an administration interface from the
channel, obtains a proxy, connects itself, and then begins
communication. The argument to the connect operations must be an
object reference, not a servant implementation, because the supplier
and consumer interfaces derive from CORBA::Object .
Therefore, the servant that implements the basic pull or push
interface must be activated before connecting it. For example (we
omit error handling for clarity):
// ... create servant and obtain a reference "thePushConsumer" ...
EventChannel eventChannel = EventChannelHelper.narrow(orb.resolve_initial_references("EventService"));
eventChannel.for_consumers().obtain_push_supplier().connect_push_consumer(thePushConsumer);
As notifications occur, the channel will call thePushConsumer.push.
The event service example in section 11.4 of the text defines a printer
as a push supplier and printer clients as pull consumers (IDL p 486-7).
The event channel is obtained from a naming service (p 489).
Since
the printer servant implementation should extend both the PrinterPOA
and PushSupplierPOA skeleton classes, a tie is used for
the latter (and PrinterImpl implements PushSupplierOperations
). The printer implementation's object reference is registered in
the naming service and the tie's object reference is passed to
connect_push_supplier (p 490). The printer implementation
keeps a reference to the channel's proxy push consumer, which it uses
to perform notification (p 491). The class PrintClient
extends
PullConsumerPOA and defines a main method
that
obtains a printer from the naming service, creates and activates a
print
client, and connects it to the channel (p 493-4). It then
performs some printer operations, and tries to obtain five
notifications (p 494-6). Of course, this is simply a demo
program: no client would perform several operations and then poll for
notification from exactly those operations. For
example, a desktop client might do a try_pull before
performing
a print operation to determine whether printing is possible, and notify
the
user if it is not. For many pull clients, the code that polls for
notification
would be in a separate thread from that which uses the supplier, in
which
case disconnect_pull_consumer would stop the try_pull
thread. For a consumer object whose only purpose is to receive
notification,
the disconnect method would deactivate the consumer. In this
example,
the event data is always the same type. If not, the consumer
would
switch on the type code.
Since the proxies obtained from an event channel implement the supplier
and consumer interfaces, channels on different hosts can be connected
to provide fault tolerance (called "federated event channels").
That
is, the proxy supplier for one channel can be connected to a proxy
consumer
on another. However, consumers receive multiple notifications for
each event.
The modules CosTypedEventComm and CosTypedEventChannelAdmin
define similar interfaces and operations for typed event communication
in which the notification data is expected to be a type agreed on by
all suppliers and consumers. (any is still used for
the data because these interfaces extend those discussed above.)
We will not discuss typed event communication in details because
it has proven to be difficult to use and implement, and the
Notification Service provides a
better mechanism for structured event data.
5.2.3 The Notification Service
The original Event Service has a number of shortcomings:
- there is no filtering or routing: all of a channel's
notifications are forwarded to all consumers
- there is no definition of or access to Quality of Serivce (QoS)
characteristics
- there are no operations to determine the existing suppliers and
consumers, or the types of notification from suppliers
- notification data is generic and must be filtered and interpreted
by consumers
The Notification Service addresses these shortcomings as follows:
- the event channel factory can create multiple channels accessible
by ID
- an event channel can create and manage multiple administration
objects of each type, and an administration object can create multiple
proxies of each type
- suppliers and consumers can attach event notification filters to
proxies
- Quality of Service properties can be accessed and configured on a
per-channel, per-admin, per-proxy, or per-event basis
- suppliers can determine the event types required by consumers of
a proxy, and vice versa
- structured events provide well-defined data structures for
notification data
By using multiple channels, admin objects and proxies, the application
can arrange for notifications from a supplier to be forwarded to those
consumers that are interested in that suppiler. Event filtering
at the proxy can be used to obtain finer-grained filtering.
Examples of QoS properties include reliability levels, event
notification timeouts, maximum buffer sizes, and maximum numbers of
suppliers and consumers.
The Notification Service is defined in six modules. Generally,
its interfaces extend the corresponding Event Service interfaces to
facilitate porting code written for the Event Service to the
Notification Service.
CosNotifyChannelAdmin::......
EventChannel (p 499) extends CosEventChannelAdmin::EventChannel, create
or access Admin objects by ID, default Admin objects, ProxySupplier
superinterface
ConsumerAdmin (p 500) extends CosEventChannelAdmin::ConsumerAdmin,
create or access Proxies by ID, ClientType is {Any, StructuredEvent,
SequenceOfEvents}, filters
EventChannelFactory (p 501) create a channel with given QoS and Admin
properties (Admin: max suppiers, consumers, event queue length)
CosNotification::Property (p 501)
QoS mgmt at event, admin or proxy level: all extend QoSAdmin
filters on admin or proxy, but not channel: extend
CosNotifyFilter::FilterAdmin (p 502)
Structured events
format p 503; Property for name-value
CosNotification::StructuredEvent, EventHeader, FixedEventHeader,
EventType p 504
optional Event Type Repository: access event type definitions by
(domain_name, type_name), especially for vertical domains
variable portion of header: optional event info (p 504-5)
body contains notification data: filterable data (properties),
remaining body (any)
Structured{Push/Pull}{Supplier/Consumer}
Event filtering
reduce network traffic and simplify consumers
CosNotifyFilter::Filter, ConstraintInfo, ConstraintExp (p 506-7) filter
encapsulates a set of constraints on notifications, constraint_grammer
gives the constraint language ("EXTENDED_TCL", Trader Constraint
Language,
is the default)
FilterFactory (p 507) obtain with EventChannel::default_filter_factory
constriant expression consists of a sequence of event types to which it
applies and a constraint language expression; variables in the
boolean expression are matched to property names in the event
to evaluate a constraint, use Filter::match, match_structured, or
match_typed; constraints are ORed: true if one constraint is
satisfied
filters for a proxy are ORed; filters for admin depend on
MyOperator (AND or OR)
"mapping filters" adjust event priority and lifetime: value are set
by supplier, but the mapping filter gives control to the consumer
QoS
Event Service left QoS as an implementation choice; QoS
properties (p 510, 505) are name-value pairs
QoS mgmt at event, admin or proxy level (extend QoSAdmin) or for event
in optional header fields (p 511); form a hierarchy
program example
Import Notification Service packages and PrinterImplStructuredPushSupplierOperations for
structured events (p 513-4). Use event channel factory if no
cahnnel in naming service (p 514). Use the default supplier
admin, set the ClientType to get a push consumer for structureed events
and narrow, and connect (p 515). The supplier creates a
structured event which facilitates filtering on job ID and user ID (p
516-7). The class PrintClient extends StructuredPullConsumerPOA
and defines NotifyPublish::offer_change whihc is called
by the channel to notify consmuers of changes to the event types
notified. The main method uses the strucutred
version of the proxy pull supplier and pull consumer, uses the
channel's default consumer admin, and connects (p 518-9). It then
creates a filter via the channel's default filter factory, adds a
constraint to the filter, and attaches the filter to the proxy (p
519-20).