Lecture 4
In-class notes: CS 505 Spring 2025 Lecture 4
Recall how we have the notion of a universal Turing machine: a machine that can simulate and solve any problem that any other Turing machine can solve. We’d like to now define a notion that is similar to this where, if you can solve one problem efficiently, then you can use that algorithm to solve a different problem (also efficiently). This leads us to the notion of reducibility.
Reducibility
As above, the idea of reducibility is that if I can solve problem (i.e., decide the language ), then I can use to solve (i.e., decide) a different language . Moreover, this is efficient: there is only a polynomial overhead in using to solve .
Definition (Polynomial-time Reducibility). Let and be languages. We say that is polynomial-time reducible to , denoted as if there exists a function that is computable in polynomial-time such that
Note that in the above definition, it is saying that if we can solve , then we can use to efficiently solve . This notation can be confusing to some people (I myself dislike it), so just be aware.
Lemma 4.1 (Reducibility is Transitive). Let , , and be languages. If and , then .
Proof. By definition, there exist functions such that
This implies that . Note that both and are polynomial-time computable, so the function is computable in polynomial time.
Since reducibility is efficient, it immediately tells us that if one of the problems is efficient, then the other is also efficient.
Theorem 4.2. If and , then .
NP-Completeness
NP-Completeness captures the ideas and goals we’ve been building so far: problems in NP that if we can solve, then we can solve any other problem in NP.
Definition (-Completeness). Let be a language. We say thta is -complete if
- The language is in : ; and
- The language is -hard: , we have .
Notice that there can be languages such that is NP-hard, but this would not be NP-complete, unless or (which we don’t know is true or not). NP-completeness captures the intuition that if we can use a language to efficiently verify every other language in NP, then this language itself should be efficiently verifiable (otherwise we just verify the other languages directly).
Unhelpful/Useless NP-Complete Language
We’ll now see an example of an NP-complete language which is not helpful for solving problems. This is because, as we’ll see, it is intimately tied to the Turing machine.
Denote by the language of all satisfiable Turing machines, defined as Here, and denote a string of (resp., ) 1’s. This is a syntactic convention we use to ensure that any machine deciding runs in time that is polynomial in and ; whereas if we specified and in binary, then the machine would only run in polynomial time with respect to the bit-length of these numbers.
Lemma 4.3. is NP-complete.
Proof. Clearly by definition. The NTM deciding takes the input , guesses the string and runs . If exceeds computational steps, output ; otherwise, output according to ( if , if ).
We now show that is NP-hard. That is, for any , we show . To do so, we define a function satisfying: . To being, let and be polynomials related to the Turing machine which verifies the language . That is, and correspond to the Turing machine which on any input and witness runs in time at most .
Now we define as follows for any .
The tuple is in if there exists such that in at most steps.
Notice that this is trivially true by definition of the NP language .
Therefore we have .
This NP-complete language isn’t useful because it’s very definition makes it trivially NP-complete. Moreover, it is inherently tied to the definition of a Turing machine. Intuitively, this says that: if you can compute the Turing machine which verifies the language , then you can compute the Turing machine which verifies the language .
Ideally, we’d like a language that is NP-complete irrespective of the computational model we use. Intuitively, we want to show that the problem itself that is captured by the language is NP-complete, which would tell us that as long as we can solve this problem (and not the Turing machine tied to the problem), then we can solve other problems in NP.
Boolean Satisfiability
The problem we will examine as a candidate for NP-completeness in this light is Boolean Satisfiability. Recall the notion of Boolean variables or Boolean literals , which take on True/False values, where we use to denote these values, respectively. Similarly, recall Boolean operations: for example, (logical OR), (logical AND), (logical XOR), (logical NOT, denoted as ), etc. Then, a Boolean expression or Boolean formula is an expression involving Boolean variable and operations (e.g., ). We define the length or size of a Boolean formula to be the number of non- operations in a formula.
For our purposes, we will only consider Boolean formulas which consist of AND, OR, and NOT. It is a well-known fact that these three operations are universal: any Boolean formula can be rewritten as an equivalent formula using only AND, OR, and NOT. Finally, we say that a Boolean formula is satisfiable if there exists an assignment of the variable such that .
Now, the language of Boolean Satisfiability is defined as follows.
How powerful is ? One measure of its power is the collapse of P vs. NP if we find a polynomial-time algorithm for deciding .
Theorem 4.4. .
Cook-Levin Theorem: SAT is NP-complete
In the 1970’s, Cook and Levin independently showed that is NP-complete. This means that if we can find a satisfying assignment for Boolean formulas, we can solve any problem in NP. We’ll begin proving this theorem, then wrap up the proof in the next lecture.
Theorem 4.5 (Cook-Levin). is NP-complete.
Proof. We must show that and that is NP-hard. The first task is straightforward. For the second task, at a high level, we must construct a polynomial-time reduction from any language to an instance of . This reduction must have the property that the instance is satisfiable if and only if membership in is true. Conceptually, we’ll construct a Boolean formula which encodes the correctness of the Turing machine deciding the language . At a high-level, this is a simple task, but the devil is in the details with this reduction.
To begin, we show that . We give a simple NTM deciding . Let be a Boolean formula and suppose has literals . Then, the machine on input simply guesses a satisfying assignment for , checks if evaluates to under this assignment, then accepts or rejects accordingly. Clearly, is a NTM which decides , and the running time of is clearly polynomial in the length of .
We now turn to showing that is NP-hard. Before doing this, we switch to the convention of single-tape non-deterministic Turing machines. That is, we’ll use the definition of NP languages where if and only if there is a single-tape NTM which decides in polynomial time. Since, like deterministic machines, many-tape NTMs are (polynomially equivalent to) single-tape NTMs, everything remains in NP.
The idea behind the reduction is the following. Let with single-tape NTM deciding , and consider any .1 The reduction (i.e., the function ) will first map the execution of to a table representing this execution. Then, the reduction will specify a Boolean formula that is satisfiabile if and only if this table representing the execution is correct and accepts the input ; otherwise the formula will be unsatisfiable.
Assume that on inputs of length , the machine runs in time for some constant (for convenience in the proof, we actually assume the runtime is , but this is a minor detail). We’ll construct a table representing the computation of of size . Every row of the table has the following properties:
- The start and end of every row is filled with a special symbol , where is the tape alphabet of . We’ll index the start of the row by .2
- For every row , the cells between the start and end symbols contain the contents of ’s single tape, plus its current state .
The current state is used to represent the current position of ’s single tape head.
- If is at position in the row for , then the tape head is reading from position in the table (which corresponds to the tape head being above position on ’s tape (here, we start indexing ’s tape at ).
- The first row of the table (row ) always has the starting configuration of . This corresponds to the tuple .
Since runs in time at most , it can read/write to/from at most cells on its work tape. This is exactly the number of slots in a row of table which are dedicated to the work tape configuration, plus 2 slots for , and one more slot for the current state.

Our goal is to define a Boolean formula capturing the correctness of the table representing . To do this, we first set up the alphabet of the table. Let . We call the table alphabet. We let denote a cell of the table for all .
For every cell and every , we define a unique Boolean literal . This literal represents the statement “”. In particular, if , then we would set , and if , then we’d set . The reverse is also true; the literal being means the cell contains that element from , and being means it does not.
Using these literals, we’ll now encode the correctness of the table for into a Boolean formula . This formula is going to be the conjunction (i.e., logical AND) of 4 sub-formulas:
The formula is simple: it will represent the correct starting configuration of the machine. This is a straightforward AND of many literals, shown below:
Next, the formula will check that the table is an accepting table. That is, it will check that there exists at least one accepting state somwhere in the table. Note that we do not care where this accepting state is, nor if there is also a rejecting state, located in the table; we will handle these consistency checks with . Since all we care about is there is at least one accepting state, we can simply take a large OR of all the cells, yielding:
The formula is going to make sure that every cell of the table only contains a single element of . That is, we check to make sure that (1) every cell contains an element of , and (2) every cell only contains a single element of . For (1), we can check this with a simple OR. Let . Then we can check if contains an element of using the expression If this is true, we know that .
Now we ensure that only contains a single value from . This is done by making sure that for all such that , the expression is true. This expression evaluates to false when contains both and . If it contains at most one of or (including neither of them), then this expression is satisfied. Then we check that this holds over all . Thus, (2) is captured by the formula=
Therefore, a single cell is valid if both (1) and (2) hold. We then check that this condition holds for all possible cells, yielding our final expression
Finally, we turn to the formula . The goal of is to ensure that the table we’ve constructed is a correct execution of the Turing machine on input . Intuitively, this involves confirming that transitioning from configuration to was valid (according to the transition function of ); i.e., that row in the table is consistent with row . Unfortunately, trying to cook up a small (i.e., polynoimal-sized) formula for checking row vs. of the entire row seems to not be possible (e.g., this could take many logical ORs of some -sized sub-formulas). Fortunately, it is enough for us to look at small windows of the table representing ’s computation.
This is (one of the many) beautiful parts of the Cook-Levin theorem. Intuitively, this “looking at windows” to check consistency showcases how highly local Turing machine computations are. As we will see, we will be able to completely verify the entire computation of the Turing machine by scanning over all windows in the given table.
For and , define as the the following matrix with entries from : We say that window is legal if this window does not violate the actions of the transition function .
Rather than be super formal with this definition (which does not help with intuition), we’ll see some examples of legal windows. First suppose that and let be states of . Now suppose the transition function is defined as follows (for this limited example):
-
; i.e., while in state , if is read from under the tape head, write under the tape head, then move the tape head right and stay in state .
-
; i.e., while in state , if is read from under the tape head, non-deterministically choose whether to
- write under the tape head, move the tape head left, then change to state ; or
- write under the tape head, move the tape head right, then change to state .
With respect to this transition function, the following windows would be considered legal.
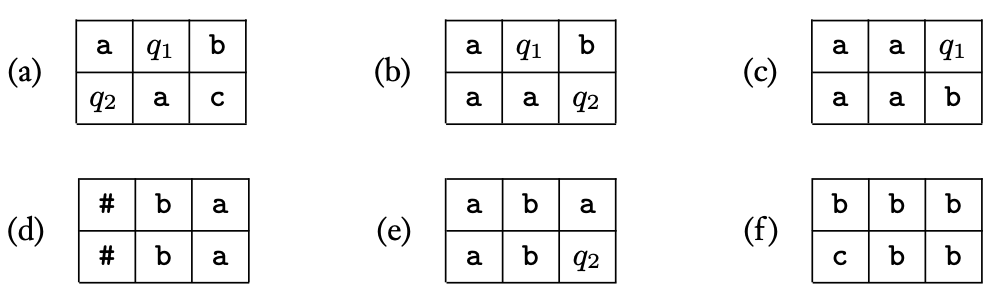
In this figure, windows (a) and (b) are legal because the transition function specifies these are legal actions (recall that the tape head reads the symbol next to the state in the table). Now window (c) is legal because with appearing on the top right, then the symbol appearing in the bottom right, this was possible if the symbol were to the right of and then moved right (as specified by ). Window (d) is legal because the top and bottom are identical, indicating that the tape head is nowhere near these positions and therefore could not have modified them. Also, it is legal for to be in the left column (they can also appear in the right column, but never in the center column). Window (e) is legal because state might have been to the immediate right of the top row, a may have been read, then the tape head may have moved left and transitioned to state , which is a valid transition under . Finally, window (f) is legal because may be to the immediate left of the first row, read , wrote then moved left, which is valid under .
Now with respect to this transition function, here are examples of illegal windows.

In the above figure, window (a) is illegal since the tape head was not in a position to change to . Window (b) is illegal since the while in state and reading a , the transition function does not allow the machine to write then move left and change to state . Window (c) is illegal because there are two states specified in the bottom row.
Now, intuitively, we want to specify as the formula This says that all possible windows are legal. In the next lecture, we’ll see that this is enough to show the entire Turing machine computation is valid.