Duration: 6/17/2025-6/30/2030
PI: Wei Tang (tangw@uic.edu)
Date of Last Update: 6/13/2026
The physical world is compositional. A scene is composed of various objects arranged in a way that is governed by physical laws. Each object consists of distinct parts that determine its functionality and affordances. For example, in a scene, the laws of gravity mean that chairs will be arranged on the floor and the rules of functionality dictate that the chair will have enough balance through its base or legs to support a person. Because the image is arranged based on the physical laws and functionality, it makes understanding the scene simpler. This project aims to develop a computer vision framework that learns and understands the physical world in a compositional manner, offering two significant benefits. First, a compositional interpretation of objects and scenes enables intelligent systems to engage in richer physical interactions and accomplish more complex tasks. Second, by decomposing complex entities into simpler constituents and modeling their relationships, this compositional approach addresses fundamental challenges faced by purely data-driven methods, including data inefficiency, the curse of dimensionality, and limited explainability. The outcomes of this project will impact a wide range of emerging applications, including robots that support manufacturing or assist with daily tasks, autonomous vehicles that enhance mobility and safety, and virtual or augmented reality interfaces that facilitate assistive workflows and remote collaboration. This project will tightly integrate research and education through curriculum development, research training for high school, undergraduate, and graduate students, and community outreach.
This project will develop new methodologies for learning and understanding the innate compositionality of objects and scenes in the physical world. It consists of three innovative thrusts. Thrust I aims to establish a unified framework for representing, parsing, and learning the compositionality of physical objects, through disentangled modeling of large shape variations, constituent parts, and detailed deformations of each part as multi-granularity neural fields. Thrust II aims to develop a new compositional model that parses 3D dynamic scenes from streaming video into an explainable layout graph on the fly, by constructing distributed representations of low-level geometry and motion and performing explicit reasoning about high-level scene compositionality. Thrust III will extend the first two thrusts by modeling the compositionality of generic articulated objects and investigating test-time adaptation for 3D dynamic scene parsing. Distinct from purely data-driven methods, this new compositional paradigm reduces reliance on extensive 3D annotations, naturally handles the high dimensionality of geometry and motion, and enables a deeper, more explainable understanding of the physical world. This project will advance and enrich fundamental research in visual compositionality, physical object and scene understanding, and explainable parsing.
(a) Part-whole Structure of Physical Objects
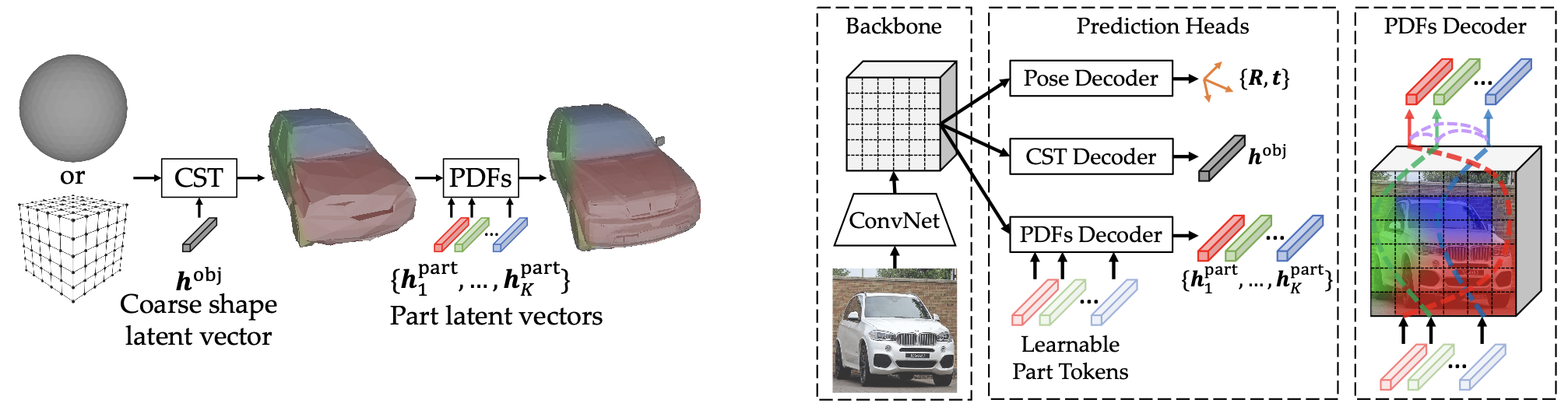
We developed the first method that learns the part-whole structure of physical objects from image data using only 2D annotations.
This approach comprises: (1) a compact and expressive compositional representation of object geometry, achieved through disentangled modeling of large shape variations, constituent parts, and detailed part deformations as multi-granularity neural fields; (2) a part-based transformer that recovers precise partonomic geometry and handles occlusions, through effective part-to-pixel grounding and part-to-part relational modeling; and (3) a self-supervised method that jointly learns the compositional representation and part-based transformer, by bridging object shape and parts, image synthesis, and differentiable rendering. Extensive experiments on ShapeNetPart, PartNet, and CUB-200-2011 demonstrate the effectiveness of our approach on both object and part reconstruction.
Xiaoqian Ruan, Pei Yu, Dian Jia, Hyeonjeong Park, Peixi Xiong, and Wei Tang, “Learning Partonomic 3D Reconstruction from Image Collections,” IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. [Code]
(b) Vision-Language-Shape Model

We introduced the first work on open-vocabulary partonomic 3D reconstruction from a single image. The key is a novel vision-language-shape (VLS) model that unifies vision, language, and shape representations within a shared neural field and grounds continuous 3D coordinates to 2D
pixel context via a deformable implicit function. It can effectively reconstruct any-topology shapes and open-vocabulary parts from a single image. To train VLS with limited 3D part-labeled data, we propose an omni-supervised learning framework that leverages heterogeneous datasets with different levels
of annotation and open-world knowledge from existing vision-language models. Extensive experiments on ShapeNetPart, PartNet, and Objaverse demonstrate the
effectiveness and strong generalization ability of VLS. We will release the code
and data publicly.
Xiaoqian Ruan, Pei Yu, Dian Jia, Hyeonjeong Park, Peixi Xiong, Wei Tang, “VLS: A Vision-Language-Shape Model for Open-Vocabulary Partonomic 3D Reconstruction,” Submission under Review, 2026.
(c) Uncertainty in 3D Scene Understanding
We explored monocular 3D scene understanding, including 3D object detection and occupancy prediction, in uncertain scenarios. First, we developed a multi-hypothesis framework that explicitly models and learns the multimodal distribution of plausible 3D object configurations to tackle depth ambiguity. Second, we introduced class-disentangled 3D volumetric representations and modeled their spatial interactions to handle class imbalance and occlusion. Third, we proposed a ranking-and-retrieval mechanism to improve both 3D localization and confidence estimation.
Hyeonjeong Park, Peixi Xiong, Xiaoqian Ruan, Dian Jia, Pei Yu, and Wei Tang, "RARE: Learn to Rank and Retrieve for Monocular 3D Object Detection," IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026. [Code]
Dian Jia, Pei Yu, and Wei Tang, "FairScene: Learning Class-Disentangled 2D/3D Representations for Semantic Scene Completion," IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2026. [Code]
Hyeonjeong Park, Peixi Xiong, Pei Yu, and Wei Tang, "Modeling and Learning Multiple Hypotheses for Monocular 3D Object Detection," in IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2026. [Code]
(a) Graduate Student Training and Development. This project has provided valuable training and professional development opportunities for three Ph.D. students in the PI's research group at the University of Illinois Chicago (UIC).
(b) Undergraduate Mentorship. The PI has continued serving as a Faculty Fellow in the Honors College at UIC, and he is currently mentoring one undergraduate student in this program. In addition, the PI has been advising an undergraduate student from his course on robot perception.
(c) K-12 Research Experience. The PI has served as a mentor for the 2025-2026 Argonne STARS program. Through this program, the PI advised a student at Neuqua Valley High School on computational modeling of gene expression recovery after traumatic brain injury.
(d) Interdisciplinary Collaboration and Applications. The PI has been working on applying the techniques from this project on assessment of secondary lymphedema in head and neck cancer (with Professor Elisabeta Marai and Professor Clifton David Fuller) and on autonomous robotics (with Professer Milos Zefran).
This material is based upon work supported by the National Science Foundation under Grant No. IIS-2442540. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of the National Science Foundation.