© Copyright Mark Grechanik 2012

Automatically SyntheSizing Software Integration Tests
We created a novel approach for Automatically SyntheSizing Integration Software Tests (ASSIST)
that automatically obtains models that describe frequently interacting components in software
applications, thus reducing the number of synthesized integration tests and increasing their bug-
finding power. In ASSIST, static and dynamic analyses are used along with carving runtime states to
obtain test input data as well as oracles for the synthesized integration tests. We experimented with
three Java applications and show that integration tests that are synthesized using ASSIST have
comparable bug finding power with manually created integration tests. You can learn more from our
ASSIST website.
Provisioning Resources with performancE Software Test
automatiOn (PRESTO)
Cloud computing is a system service model in which stakeholders deploy and run their software applications on a sophisticated infrastructure that is owned and managed by third- party providers. The ability of a given cloud infrastructure to effectively re-allocate resources to applications is referred to as elasticity. Of course, in practice, clouds are not perfectly elastic. Since cloud providers must provide elastic cloud services to a wide range of customers, their cloud platforms do not provision their resources precisely and automatically for specific applications. At the same time it is currently infeasible for cloud providers to allow customers to guide the cloud on how best to elastically provision their applications. To significantly reduce the cost of deploying software applications in the cloud, we solve a fundamental problem at the intersection of cloud computing and software performance testing. Our core idea is to automatically learn behavioral models of software applications during performance testing to synthesize provisioning strategies that are automatically tailored for these applications. With our idea, the problem of precise cloud elasticity is translated into enabling a feedback-directed loop between software development and cloud deployment. We implemented our approach and applied it to two software applications in the cloud environment, namely Cloudstack. Our experiments demonstrate that with our approach the cloud is able to provision resources more efficiently, so that the applications improve their throughput by up to over 40%. You can learn more from our PRESTO website. Java Mutation Integration Testing (jMINT) We created a solution for Java Mutation Integration Testing (jMINT) to generate mutants that specifically target integration tests. We conducted empirical investigation into integration bugs that were reported in bug repositories for popular open-source projects. Based on this empirical investigation, we formulated a fault model for integration bugs that gave us a key insight of using static dataflow analysis to obtain information about how different components interact in an application. We use this information to generate mutants by applying mutation operators to dataflow paths through which components exchange data. We implement our ideas in a tool and we evaluate this tool on five open-source applications and compare it with muJava, a publicly available mutation tool for Java. Our evaluation shows that even though jMINT takes approximately five times more memory in the worse case, it leads to reduction of the number of generated mutants by up to five times, with an increased mutant killing ratio and approximately the same mutant generation time. . You can learn more from our jMINT website.Enhancing Performance and rEliability of RuLe-driven
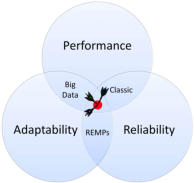
ApplicaTiOns (PERLATO)
RulE Management Platforms (REMPs) allow software engineers to represent programming logic as conditional sentences that relate statements of facts (i.e., rules). A fundamental problem of REMPs lies at the intersection of performance, adaptability and reliability of rule- driven applications. In today’s rapidly changing business requirements, software adaptability is critical element that ensures success. REMPs provide software adaptability by burying the complexity of rule invocation in REMP engines and enabling stakeholders to concentrate on business aspects of highly modular rules. Naturally, rule-driven applications should exhibit excellent performance, since REMP engines should be able to invoke highly modular rules in parallel in response to asserting different facts. In reality, it is a hard and open problem to parallelize the execution of rules, since it leads to the loss of reliability and adaptability of rule-driven applications. Our preliminary results show that possible races can be detected statically among rules, and we created an algorithm for automatically preventing these races inside the REMP engine. Next, we use sensitivity analysis to find better schedules among simultaneously executing rules to improve the overall performance of the application. We implemented our solution for JBoss Drools and we evaluated it on three applications. The results suggest that our solution is effective, since we achieved over 225% speedup on average. You can learn more from our PERLATO website.Protecting and minimizing databases for Software Testing
taSks (PISTIS)
We created a novel approach for Protecting and mInimizing databases for Software TestIng taSks (PISTIS) that both sanitizes a database and minimizes it. PISTIS uses a weight-based data clustering algorithm that partitions data in the database using information from program analysis that indicate how this data is used by the application. For each cluster, a centroid object is computed that represents different persons or entities in the cluster, and we use associative rule mining to compute and use constraints to ensure that the centroid objects are representative of the general population of data in the cluster. Doing so also sanitize information, since these centroid objects replace the original data to make it difficult for attackers to infer sensitive information. Thus, we reduce a large database to a few centroid objects and we show in our experiments with four applications that test coverage stays within a close range to its original level. You can learn more from our PISTIS website.ENhancing TRAceability usiNg API Calls and rElevant woRds
(ENTRANCER)
Software traceability is the ability to describe and follow the life of a requirement in both a forward and backward direction by defining relationships to related development artifacts. A plethora of different traceability recovery approaches use information retrieval techniques, which depend on the quality of the textual information in requirements and software artifacts. Not only is it important that stakeholders use meaningful names in these artifacts, but also it is crucial that the same names are used to specify the same concepts in different artifacts. Unfortunately, the latter is difficult to enforce and as a result, software traceability approaches are not as efficient and effective as they could be - to the point where it is questionable whether the anticipated economic and quality benefits were indeed achieved. We propose a novel and automatic approach for expanding corpora with relevant documentation that is obtained using external function call documentation and sets of relevant words, which we implemented in TraceLab. We experimented with three Java applications and we show that using our approach the precision of recovering traceability links was increased by up to 31% in the best case and by approximately 9% on average. You can learn more from our ENTRANCER website.PRedicting software qualIty with Minimum fEatures (PRIME)
Predicting software quality is important for multiple reasons including planning resource allocation for software development and maintenance, evaluating the cost, and suggesting delivery dates for software applications. It is not clear how well the quality of software can be predicted - multiple studies report mixed results when using different software metrics. A common denominator for most of these studies is small numbers of subject software applications and internal software metrics, and narrowly specialized measures of software quality. Thus, a fundamental problem of software engineering is if software quality can be accurately predicted using internal software metrics alone. We reformulated this problem as a supervised machine learning problem to verify if collectively these software metrics are predictors of software quality. To answer this question, we conducted a large- scale empirical study with 3,392 open-source projects using six different classifiers. Further, we performed feature selection to determine if a subset of these metrics could do so to guard against noise and irrelevant attributes. Our results show that the accuracy of software quality prediction stays below 61% with Cohen's and Shah's kappa << 0.1 leading us to suggest that comprehensive sets of internal software metrics alone are unlikely to accurately predict software quality in general. You can learn more from our PRIME website. Sanitizing And Minimizing Databases For Software Testing We created a novel approach for Protecting and mInimizing databases for Software TestIng taSks (PISTIS) that both sanitizes a database and minimizes it. PISTIS uses a weight-based data clustering algorithm that partitions data in the database using information from program analysis that indicate how this data is used by the application. For each cluster, a centroid object is computed that represents different persons or entities in the cluster, and we use associative rule mining to compute and use constraints to ensure that the centroid objects are representative of the general population of data in the cluster. Doing so also sanitize information, since these centroid objects replace the original data to make it difficult for attackers to infer sensitive information. Thus, we reduce a large database to a few centroid objects and we show in our experiments with four applications that test coverage stays within a close range to its original level. You can learn more from our PISTIS website. Feedback-Directed Learning Software Performace Testing A goal of performance testing is to find situations when applications unexpectedly exhibit worsened characteristics for certain combinations of input values. A fundamental question of performance testing is how to select a manageable subset of the input data faster to find performance problems in applications automatically. We created a novel solution for finding performance problems in applications automatically using black-box software testing. Our solution, FOREPOST shows how an adaptive, feedback-directed learning testing system learns rules from execution traces of applications and then uses these rules to select test input data automatically for these applications to find performance problems. You can learn more from our FOREPOST website.Testing Applications For Causes of Database Deadlocks
We created a novel approach for Systematic TEsting in Presence of DAtabase Deadlocks (STEPDAD) that enables testers to instantiate database deadlocks in applications with a high level of automation and frequency. STEPDAD reproduced a number of database deadlocks in these applications that is bigger by more than an order of magnitude on average when compared with the number of reproduced database deadlocks using the baseline approach. In some cases, STEPDAD reproduced a database deadlock after running an application only two times, while no database deadlocks were reproduced after ten runs using the baseline approach. You can learn more from our STEPDAD website.Preventing Database Deadlocks in Software Applications
We created a novel approach for preventing database deadlocks automatically, and we rigorously evaluated it. For a realistic case of over 1,000 SQL statements, all hold-and-wait cycles are detected in less than 15 seconds. We build a tool that implements our approach and we experimented with three applications. Our tool prevented all existing database deadlocks in these applications and increased their throughputs by approximately up to three orders of magnitude. You can learn more from our REDACT website.PRivacy Equalizer for Software Testing (PRIEST)
Database-centric applications (DCAs)} are common in enterprise computing, and they use nontrivial databases. Testing of DCAs is increasingly outsourced to test centers in order to achieve lower cost and higher quality. When proprietary DCAs are released, their databases should also be made available to test engineers. However, different data privacy laws prevent organizations from sharing this data with test centers because databases contain sensitive information. Currently, testing is performed with anonymized data, which often leads to worse test coverage (such as code coverage) and fewer uncovered faults, thereby reducing the quality of DCAs and obliterating benefits of test outsourcing. To address this issue, we created a novel approach that combines program analysis with a new data privacy framework that we design to address constraints of software testing. With our approach, organizations can balance the level of privacy with needs of testing. We have built a tool for our approach and applied it to nontrivial Java DCAs. Our results show that test coverage can be preserved at a higher level by anonymizing data based on their effect on corresponding DCAs.. You can download our FSE paper and learn more from our PRIEST website.aChieving higher stAtement coveRage FASTer (CarFast)
We created a novel approach for aChieving higher stAtement coveRage FASTer (CarFast) using the intuition that higher statement coverage can be achieved faster if input data are selected to drive the execution of the AUT toward branches that contain more statements. That is, if the condition of a control-flow statement is evaluated to true, some code is executed in the scope of this statement. You can download our FSE paper.Detecting Closely reLated ApplicatioNs (CLAN)
We created a novel approach for automatically detecting Closely reLated ApplicatioNs (CLAN) that helps users detect similar applications for a given Java application. Our main contributions are an extension to a framework of relevance and a novel algorithm that computes a similarity index between Java applications using the notion of semantic layers that correspond to packages and class hierarchies. We have built CLAN and we conducted an experiment with 33 participants to evaluate CLAN and compare it with the closest competitive approach, MUDABlue. The results show with strong statistical significance that CLAN automatically detects similar applications from a large repository of 8,310 Java applications with a higher precision than MUDABlue. You can download our ICSE paper.Portfolio: A Novel Code Search Engine
We created a novel code search system called Portfolio that supportsprogrammers in finding relevant functions that implement high level requirements reflected in query terms (i.e., finding initial focus points), determining how these functions are used in a way that is highly relevant to the query (i.e., building on found focus points), and visualizing dependencies of the retrieved functions to show their usages. Portfolio finds highly relevant functions in close to 270 Millions LOC in projects from FreeBSD Ports by combining various natural language processing (NLP) and indexing techniques with PageRank and spreading activation network (SAN) algorithms. You can download our ICSE paper .REST: Reducing Effort in Script-based Testing
We created a novel approach for maintaining and evolving test scripts so that they can test new versions of their respective GUI-based Applications. We built a tool to implement our approach, and we conducted a case study with forty five professional programmers and test engineers to evaluate this tool. The results show with strong statistical significance that users find more failures and report fewer false positives (p<0.02) in test scripts with our tool than with a flagship industry product and a baseline manual approach. Our tool is lightweight and it takes less than eight seconds to analyze approximately 1KLOC of test scripts.. You can download our ICSE paper or switch to REST website .REdacting Sensitive Information in Software arTifacts
(RESIST)
In the past decade, there have been many well-publicized cases of leaking source code that contains sensitive information from different well-known companies including Cisco, Facebook, and Microsoft. Clearly, sensitive information should be redacted in source code and other software artifacts. A fundamental problem at the intersection of software maintenance and evolution and data privacy is how to allow an application owner to release its source code and other software artifacts to different service providers with guarantees that sensitive information cannot be easily inferred while preserving program comprehension, which is important for job functions of different stakeholders. To address this problem, we offer a novel approach for automatically REdacting Sensitive Information in Software arTifacts (RESIST) that combines a privacy metric, associative rule mining for finding sensitive and replacement words, a program comprehension metric, and a sound renaming algorithm for Java programs. You can watch our movie about RESIST here .Random Utility Generator for pRogram Analysis and Testing
(RUGRAT)
We created a Random Utility Generator for pRogram Analysis and Testing (RUGRAT), which is a novel languageindependent approach and a tool for generating application benchmarks within specified constraints and within the range of predefined properties. RUGRAT is implemented for Java and it is used to evaluate different open-source program analysis and testing tools. You are download our WODA paper or switch to RUGRAT website.