Data Equity Systems
Projects related to Responsible Data Science and Algorithmic Fairness

Fig 1. Bias and Fairness in Data Analytics Pipeline
Algorithmic Fairness


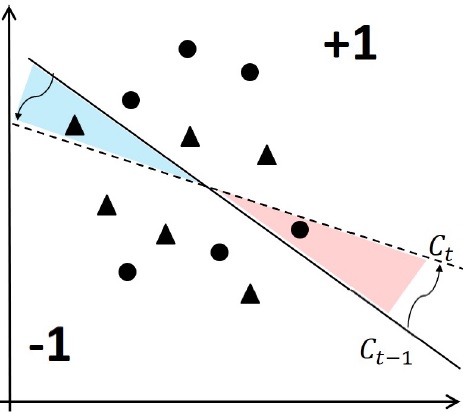
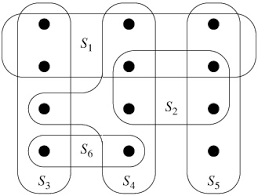
Bias in Data

More Resources:
- (Blog Post) Abolfazl Asudeh. Enabling Responsible Data Science in Practice. ACM SIGMOD Blog, Jan. 2021.
- (Tutorial) Fatemeh Nargesian, Abolfazl Asudeh, H. V. Jagadish. Responsible Data Integration: Next-generation Challenges. SIGMOD, 2022, ACM.
- (Tutorial) Abolfazl Asudeh, HV Jagadish. Fairly Evaluating and Scoring Items in a Data Set. PVLDB, 2020, VLDB Endowment.
- (Survey) Nima Shahbazi, Yin Lin, Abolfazl Asudeh, HV Jagadish. Data-Centric Distrust Quantification for Responsible AI: When Data-driven Outcomes Are Not Reliable. CoRR, 2022.
- (Invited Paper) Abolfazl Asudeh, HV Jagadish, Julia Stoyanovich. Towards Responsible Data-driven Decision Making in Score-Based Systems. Data Engineering Bulletin, Vol. 42(3), pages 76--87, 2019, Special Issue on Fairness, Diversity, and Transparency in Data Systems.

Computational Fact Checking and Bias in Data Presentation
Projects related to Computational Fact Checking
In this project, we particularly are interested to detect mileading information and statements made by cherry-picking data.
This is popular among politicians since they would like not to be caught blatantly lying.
That is why "A lie which is half a truth is ever the blackest of lies" (A.Tennyson).
But how to computationally detect/measure "half a truth"?
We aim to address this question in this project.
This project has been supported by the Google Scholar Award.
More details in Project Page.

Orca
Projects related to Computation at Scale
Scalability has always been a challenge in CS.
Just like Orcas who find smart ways to hunt the giants (watch these: [1], [2]),
we aim to design efficient and accurate algorithms that can solve problems at scale.
More details in Project Page.

Ranking & Representatives
Projects related to Ranking and Top-k query processing; Skyline and Regret-Minimizing sets
Evaluating objects, ranking them, and selecting the "best", is the key to decision making and a fundumental CS problem. However, almost as critical it is, ranking has always been controversial. Probably the main reason is that the concept of "best" lies in the eyes of the beholder and there can be many criteria involoved. Examples range from simple daily tasks such as booking a hotel or choosing a photo to post, to evaluating candidates for college admission, ranking universities, you name it.
Finding novel, efficient, and accurate technical solutions for addressing the challenging problems in this area is our focus here.
More details in Project Page.

AI&ML
Projects related to AI and machine learning
We specifically target data prepration and leveraging data management techniques for machine learning. Some of our projects in this area include creating nutritional labels for dataset, efficient construction of ad-hoc ML models, and fairness in ML.
More details in Project Page.

Web DataX
Projects related to Web Data Exploration
Web databases, also known as deep web or hidden web databases, cover a large portion of web.
This includes shopping websites such as Amazon and eBay,
service search sites such as Expedia and Google Flights,
recommendation websites, and P2P marketplaces such as Airbnb and Craigslist.
With minor differences, such systems have a typical structure that enforce a ranked retrieval interface.
Our projects in this category enable efficient data exploration and flexible query answering and recommendation in this environment.
More details in Project Page.